ABOUT US
We are security engineers who break bits and tell stories.
Visit us
doyensec.com
Follow us
@doyensec
Engage us
info@doyensec.com
Blog Archive
© 2026 Doyensec LLC 
Logistics and shipping devices across the world can be a challenging task, especially when dealing with customs regulations. For the past few years, I have had the opportunity to learn about these complex processes and how to manage them efficiently. As a Practice Manager at Doyensec, I was responsible for building processes from scratch and ensuring that our logistics operations ran smoothly.
Since 2018, I have had to navigate the intricate world of logistics and shipping, dealing with everything from international regulations to customs clearance. Along the way, I have learned valuable lessons and picked up essential skills that have helped me manage complex logistics operations with ease.

In this post, I will share my experiences and insights on managing shipping devices across the world, dealing with customs, and building efficient logistics processes. Whether you’re new to logistics or looking to improve your existing operations, my learnings and experiences will prove useful.
At Doyensec, when we hire a new employee, our HR specialist takes care of all the necessary paperwork, while I focus on logistics. This includes creating a welcome package and shipping all the necessary devices to the employee’s location. While onboarding employees from the United States and European Union is relatively easy, dealing with customs regulations in other countries can be quite challenging.
For instance, shipping devices from/to countries such as the UK (post Brexit), Turkey, or Argentina can be quite complicated. We need to be aware of the customs regulations in these countries to ensure that our devices are not bounced back or charged with exorbitant custom fees.
Navigating customs regulations in different countries can be a daunting task. Still, we’ve learned that conducting thorough research beforehand and ensuring that our devices comply with the necessary regulations can help avoid any unnecessary delays or fees. At Doyensec, we believe that providing our employees with the necessary tools and equipment to perform their job is essential, and we strive to make this process as seamless as possible, regardless of where the employee is located.
At Doyensec, dealing with testing hardware is a crucial aspect of our operations. We use a variety of testing equipment for our work. This means that we often have to navigate customs regulations, including the payment of customs fees, to ensure that our laptops, Yubikeys and mobile devices arrive on time.
To avoid delays in conducting security audits, we often choose to pay additional fees, including VAT and customs charges, to ensure that we receive hardware promptly. We understand that time is of the essence, and we prioritize meeting our clients’ needs, even if it means spending more money to ensure items required for testing are not held up at customs.
In addition to paying customs fees, we also make sure to keep all necessary documentation for each piece of hardware that we manage. This documentation helps us to speed up further processes and ensures that we can quickly identify and locate each and every piece of hardware when needed.
The hardware we most frequently deal with are laptops, though we also occasionally receive YubiKeys as well. Fortunately, YubiKeys generally do not cause any problems at customs (low market value), and we can usually receive them without any significant issues.
Over time, we’ve learned that different shipping companies have different approaches to customs regulations. To ensure that we can deliver quality service to our clients, we prefer to use companies that we know will treat us fairly and deliver hardware on time. We have almost always had a positive experience with DHL as our preferred shipping provider. DHL’s automated custom processes and documentation have been particularly helpful in ensuring smooth and efficient shipping of Doyensec’s hardware and documents across the world. DHL’s reliability and efficiency have been critical in allowing Doyensec to focus on its core business, which is finding bugs for our fantastic clients.
We have a preference for avoiding local post office services when it comes to shipping our hardware or documents. While local post office services may be slightly cheaper, they often come with more problems. Packages may get stuck somewhere during the delivery process, and it can be difficult to follow up with customer service to resolve the issue. This can lead to delayed deliveries, frustrated customers, and ultimately, a negative impact on the company’s reputation. Therefore, Doyensec opts for more reliable shipping options, even if they come with a slightly higher price tag.
At Doyensec, we believe in showing appreciation for our employees and their hard work. That’s why we decided to import some gifts from Japan to distribute among our team members. However, what we did not anticipate was the range of custom fees that we would encounter while shipping these gifts to different countries.
We shipped these gifts to 7 different countries, all through the same shipping company. However, we found that custom officers had different approaches even within the same country. This resulted in a range of custom fees, ranging from 0 to 45 euros, for each package.
The interesting part was that every package had the same invoice from the Japanese manufacturer attached, but the fees still differed significantly. It was challenging to understand why this was the case, and we still don’t have a clear answer.
Overall, our experience with importing gifts from Japan highlighted the importance of being prepared for unexpected customs fees and the unpredictability of customs regulations.
Managing devices and shipping packages to team members at a globally distributed company, even with a small team, can be quite challenging. Ensuring that packages are delivered promptly and to the correct location can be very difficult, especially with tight project deadlines.
Although it would be easier to manage devices if everyone worked from the same office, at Doyensec, we value remote work and the flexibility that it provides. That’s why we have invested in developing processes and protocols to ensure that our devices are managed efficiently and securely, despite the remote working environment.
While some may argue that these challenges are reason enough to abandon remote work and return to the office, we believe that the benefits of remote work far outweigh any challenges we may face. At Doyensec, remote work allows us to hire talented individuals from all the EU and US/Canada, offering a diverse and inclusive work environment. Remote work also allows for greater flexibility and work-life balance, which can result in happier and more productive employees.
In conclusion, while managing devices in a remote work environment can be challenging, we believe that the benefits of remote work make it worthwhile. At Doyensec, we have developed strategies to manage devices efficiently, and we continue to support remote work and its many benefits.
R2pickledec is the first pickle decompiler to support all instructions up to protocol 5 (the current). In this post we will go over what Python pickles are, how they work and how to reverse them with Radare2 and r2pickledec. An upcoming blog post will go even deeper into pickles and share some advanced obfuscation techniques.
Pickles are the built-in serialization algorithm in Python. They can turn any Python object into a byte stream so it may be stored on disk or sent over a network. Pickles are notoriously dangerous. You should never unpickle data from an untrusted source. Doing so will likely result in remote code execution. Please refer to the documentation for more details.
Pickles are implemented as a very simple assembly language. There are only 68
instructions and they mostly operate on a stack. The instruction names are
pretty easy to understand. For example, the instruction empty_dict will push
an empty dictionary onto the stack.
The stack only allows access to the top item, or items in some cases. If you
want to grab something else, you must use the memo. The memo is implemented as
a dictionary with positive integer indexes. You will often see memoize
instructions. Naively, the memoize instruction will copy the item at the top
of the stack into the next index in the memo. Then, if that item is needed
later, a binget n can be used to get the object at index n.
To learn more about pickles, I recommend playing with some pickles. Enable
descriptions in Radare2 with e asm.describe = true to get short descriptions of
each instruction. Decompile simple pickles that you build yourself, and see if you
can understand the instructions.
For reversing pickles, our tool of choice is Radare2 (r2 for short). Package managers tend to ship really old r2 versions. In this case it’s probably fine, I added the pickle arch to r2 a long time ago. But if you run into any bugs I suggest installing from source.
In this blog post, we will primarily be using our R2pickledec decompiler plugin. I purposely wrote this plugin to only rely on r2 libraries. So if r2 works on your system, r2pickledec should work too. You should be able to instal with r2pm.
$ r2pm -U # update package db
$ r2pm -ci pickledec # clean install
You can verify everything worked with the following command. You should see the r2pickledec help menu.
$ r2 -a pickle -qqc 'pdP?' -
Usage: pdP[j] Decompile python pickle
| pdP Decompile python pickle until STOP, eof or bad opcode
| pdPj JSON output
| pdPf Decompile and set pick.* flags from decompiled var names
Let’s reverse a real pickle. One never reverses without some context, so let’s imagine you just broke into a webserver. The webserver is intended to allow employees of the company to perform privileged actions on client accounts. While poking around, you find a pickle file that is used by the server to restore state. What interesting things might we find in the pickle?
The pickle appears below base64 encoded. Feel free to grab it and play along at home.
$ base64 -i /tmp/blog2.pickle -b 64
gASVDQYAAAAAAACMCF9fbWFpbl9flIwDQXBplJOUKYGUfZQojAdzZXNzaW9ulIwR
cmVxdWVzdHMuc2Vzc2lvbnOUjAdTZXNzaW9ulJOUKYGUfZQojAdoZWFkZXJzlIwT
cmVxdWVzdHMuc3RydWN0dXJlc5SME0Nhc2VJbnNlbnNpdGl2ZURpY3SUk5QpgZR9
lIwGX3N0b3JllIwLY29sbGVjdGlvbnOUjAtPcmRlcmVkRGljdJSTlClSlCiMCnVz
ZXItYWdlbnSUjApVc2VyLUFnZW50lIwWcHl0aG9uLXJlcXVlc3RzLzIuMjguMpSG
lIwPYWNjZXB0LWVuY29kaW5nlIwPQWNjZXB0LUVuY29kaW5nlIwNZ3ppcCwgZGVm
bGF0ZZSGlIwGYWNjZXB0lIwGQWNjZXB0lIwDKi8qlIaUjApjb25uZWN0aW9ulIwK
Q29ubmVjdGlvbpSMCmtlZXAtYWxpdmWUhpR1c2KMB2Nvb2tpZXOUjBByZXF1ZXN0
cy5jb29raWVzlIwRUmVxdWVzdHNDb29raWVKYXKUk5QpgZR9lCiMB19wb2xpY3mU
jA5odHRwLmNvb2tpZWphcpSME0RlZmF1bHRDb29raWVQb2xpY3mUk5QpgZR9lCiM
CG5ldHNjYXBllIiMB3JmYzI5NjWUiYwTcmZjMjEwOV9hc19uZXRzY2FwZZROjAxo
aWRlX2Nvb2tpZTKUiYwNc3RyaWN0X2RvbWFpbpSJjBtzdHJpY3RfcmZjMjk2NV91
bnZlcmlmaWFibGWUiIwWc3RyaWN0X25zX3VudmVyaWZpYWJsZZSJjBBzdHJpY3Rf
bnNfZG9tYWlulEsAjBxzdHJpY3RfbnNfc2V0X2luaXRpYWxfZG9sbGFylImMEnN0
cmljdF9uc19zZXRfcGF0aJSJjBBzZWN1cmVfcHJvdG9jb2xzlIwFaHR0cHOUjAN3
c3OUhpSMEF9ibG9ja2VkX2RvbWFpbnOUKYwQX2FsbG93ZWRfZG9tYWluc5ROdWKM
CF9jb29raWVzlH2UdWKMBGF1dGiUjAVhZG1pbpSMD1BpY2tsZXMgYXJlIGZ1bpSG
lIwHcHJveGllc5R9lIwFaG9va3OUfZSMCHJlc3BvbnNllF2Uc4wGcGFyYW1zlH2U
jAZ2ZXJpZnmUiIwEY2VydJROjAhhZGFwdGVyc5RoFClSlCiMCGh0dHBzOi8vlIwR
cmVxdWVzdHMuYWRhcHRlcnOUjAtIVFRQQWRhcHRlcpSTlCmBlH2UKIwLbWF4X3Jl
dHJpZXOUjBJ1cmxsaWIzLnV0aWwucmV0cnmUjAVSZXRyeZSTlCmBlH2UKIwFdG90
YWyUSwCMB2Nvbm5lY3SUTowEcmVhZJSJjAZzdGF0dXOUTowFb3RoZXKUTowIcmVk
aXJlY3SUTowQc3RhdHVzX2ZvcmNlbGlzdJSPlIwPYWxsb3dlZF9tZXRob2RzlCiM
BVRSQUNFlIwGREVMRVRFlIwDUFVUlIwDR0VUlIwESEVBRJSMB09QVElPTlOUkZSM
DmJhY2tvZmZfZmFjdG9ylEsAjBFyYWlzZV9vbl9yZWRpcmVjdJSIjA9yYWlzZV9v
bl9zdGF0dXOUiIwHaGlzdG9yeZQpjBpyZXNwZWN0X3JldHJ5X2FmdGVyX2hlYWRl
cpSIjBpyZW1vdmVfaGVhZGVyc19vbl9yZWRpcmVjdJQojA1hdXRob3JpemF0aW9u
lJGUdWKMBmNvbmZpZ5R9lIwRX3Bvb2xfY29ubmVjdGlvbnOUSwqMDV9wb29sX21h
eHNpemWUSwqMC19wb29sX2Jsb2NrlIl1YowHaHR0cDovL5RoVymBlH2UKGhaaF0p
gZR9lChoYEsAaGFOaGKJaGNOaGROaGVOaGaPlGhoaG9ocEsAaHGIaHKIaHMpaHSI
aHUojA1hdXRob3JpemF0aW9ulJGUdWJoeH2UaHpLCmh7SwpofIl1YnWMBnN0cmVh
bZSJjAl0cnVzdF9lbnaUiIwNbWF4X3JlZGlyZWN0c5RLHnVijAdiYXNldXJslIwU
aHR0cHM6Ly9leGFtcGxlLmNvbS+UdWIu
We decode the pickle and put it in a file, lets call it test.pickle. We
then open the file with r2. We also run x to see some hex and pd to print
dissassembly. If you ever want to know what an r2 command does, just run the
command but append a ? to the end to get a help menu (e.g., pd?).
$ r2 -a pickle test.pickle
-- .-. .- -.. .- .-. . ..---
[0x00000000]> x
- offset - 0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
0x00000000 8004 95bf 0500 0000 0000 008c 1172 6571 .............req
0x00000010 7565 7374 732e 7365 7373 696f 6e73 948c uests.sessions..
0x00000020 0753 6573 7369 6f6e 9493 9429 8194 7d94 .Session...)..}.
0x00000030 288c 0768 6561 6465 7273 948c 1372 6571 (..headers...req
0x00000040 7565 7374 732e 7374 7275 6374 7572 6573 uests.structures
0x00000050 948c 1343 6173 6549 6e73 656e 7369 7469 ...CaseInsensiti
0x00000060 7665 4469 6374 9493 9429 8194 7d94 8c06 veDict...)..}...
0x00000070 5f73 746f 7265 948c 0b63 6f6c 6c65 6374 _store...collect
0x00000080 696f 6e73 948c 0b4f 7264 6572 6564 4469 ions...OrderedDi
0x00000090 6374 9493 9429 5294 288c 0a75 7365 722d ct...)R.(..user-
0x000000a0 6167 656e 7494 8c0a 5573 6572 2d41 6765 agent...User-Age
0x000000b0 6e74 948c 1670 7974 686f 6e2d 7265 7175 nt...python-requ
0x000000c0 6573 7473 2f32 2e32 382e 3294 8694 8c0f ests/2.28.2.....
0x000000d0 6163 6365 7074 2d65 6e63 6f64 696e 6794 accept-encoding.
0x000000e0 8c0f 4163 6365 7074 2d45 6e63 6f64 696e ..Accept-Encodin
0x000000f0 6794 8c0d 677a 6970 2c20 6465 666c 6174 g...gzip, deflat
[0x00000000]> pd
0x00000000 8004 proto 0x4
0x00000002 95bf05000000. frame 0x5bf
0x0000000b 8c1172657175. short_binunicode "requests.sessions" ; 0xd
0x0000001e 94 memoize
0x0000001f 8c0753657373. short_binunicode "Session" ; 0x21 ; 2'!'
0x00000028 94 memoize
0x00000029 93 stack_global
0x0000002a 94 memoize
0x0000002b 29 empty_tuple
0x0000002c 81 newobj
0x0000002d 94 memoize
0x0000002e 7d empty_dict
0x0000002f 94 memoize
0x00000030 28 mark
0x00000031 8c0768656164. short_binunicode "headers" ; 0x33 ; 2'3'
0x0000003a 94 memoize
0x0000003b 8c1372657175. short_binunicode "requests.structures" ; 0x3d ; 2'='
0x00000050 94 memoize
0x00000051 8c1343617365. short_binunicode "CaseInsensitiveDict" ; 0x53 ; 2'S'
0x00000066 94 memoize
0x00000067 93 stack_global
From the above assembly it appears this file is indeed a pickle. We also see
requests.sessions and Session as strings. This pickle likely imports
requests and uses sessions. Let’s decompile it. We will run the command pdPf @0
~.... This takes some explaining though, since it uses a couple of r2’s
features.
pdPf - R2pickledec uses the pdP command (see pdP?). Adding an f
causes the decompiler to set r2 flags for every variable name. This will make
renaming variables and jumping to interesting locations easier.
@0 - This tells r2 to run the command at offset 0 instead of the current
seek address. This does not matter now because our current offset defaults to
~.. - This is the r2 version of |less. It uses r2’s built in pager. If
you like the real less better, you can just use |less. R2 commands can be
piped to any command line program.Once we execute the command, we will see a Python-like source representation of the pickle. The code is seen below, but snipped. All comments below were added by the decompiler.
## VM stack start, len 1
## VM[0] TOP
str_xb = "__main__"
str_x16 = "Api"
g_Api_x1c = _find_class(str_xb, str_x16)
str_x24 = "session"
str_x2e = "requests.sessions"
str_x42 = "Session"
g_Session_x4c = _find_class(str_x2e, str_x42)
str_x54 = "headers"
str_x5e = "requests.structures"
str_x74 = "CaseInsensitiveDict"
g_CaseInsensitiveDict_x8a = _find_class(str_x5e, str_x74)
str_x91 = "_store"
str_x9a = "collections"
str_xa8 = "OrderedDict"
g_OrderedDict_xb6 = _find_class(str_x9a, str_xa8)
str_xbc = "user-agent"
str_xc9 = "User-Agent"
str_xd6 = "python-requests/2.28.2"
tup_xef = (str_xc9, str_xd6)
str_xf1 = "accept-encoding"
...
str_x5c9 = "stream"
str_x5d3 = "trust_env"
str_x5e0 = "max_redirects"
dict_x51 = {
str_x54: what_x16c,
str_x16d: what_x30d,
str_x30e: tup_x32f,
str_x331: dict_x33b,
str_x33d: dict_x345,
str_x355: dict_x35e,
str_x360: True,
str_x36a: None,
str_x372: what_x5c8,
str_x5c9: False,
str_x5d3: True,
str_x5e0: 30
}
what_x5f3 = g_Session_x4c.__new__(g_Session_x4c, *())
what_x5f3.__setstate__(dict_x51)
str_x5f4 = "baseurl"
str_x5fe = "https://example.com/"
dict_x21 = {str_x24: what_x5f3, str_x5f4: str_x5fe}
what_x616 = g_Api_x1c.__new__(g_Api_x1c, *())
what_x616.__setstate__(dict_x21)
return what_x616
It’s usually best to start reversing at the end with the return line. That is
what is being returned from the pickle. Hit G to go to the end of the file.
You will see the following code.
str_x5f4 = "baseurl"
str_x5fe = "https://example.com/"
dict_x21 = {str_x24: what_x5f3, str_x5f4: str_x5fe}
what_x616 = g_Api_x1c.__new__(g_Api_x1c, *())
what_x616.__setstate__(dict_x21)
return what_x616
The what_x616 variable is getting returned. The what part of the variable
indicates that the decompiler does not know what type of object this is. This
is because what_x616 is the result of a g_Api_x1c.__new__ call. On the
other hand, g_Api_x1c gets a g_ prefix. The decompiler knows this is a
global, since it is from an import. It even adds the Api part in to hint at
what the import it. The x1c and x616 indicate the offset in the pickle
where the object was created. We will use that later to patch the pickle.
Since we used flags, we can easily rename variables by renaming the flag. It
might be helpful to rename the g_Api_x1c to make it easier to search for.
Rename the flag with fr pick.g_Api_x1c pick.api. Notice, the flag will tab
complete. List all flags with the f command. See f? for help.
Now run pdP @0 ~.. again. Instead of g_Api_x1c you will see api. If we
search for its first use, you will find the below code.
str_xb = "__main__"
str_x16 = "Api"
api = _find_class(str_xb, str_x16)
str_x24 = "session"
str_x2e = "requests.sessions"
str_x42 = "Session"
g_Session_x4c = _find_class(str_x2e, str_x42)
Naively, _find_class(module, name) is equivalent to
_getattribute(sys.modules[module], name)[0]. We can see the module is
__main__ and the name is Api. So the api variable is just __main__.Api.
In this snippet of code, we see the request session being imported. You may
have noticed the baseurl field in the previous snippet of code. Looks like
this object contains a session for making backend API requests. Can we steal
something good from it? Googling for “requests session basic authentication”
turns up the auth attribute. Let’s look for “auth” in our pickle.
str_x30e = "auth"
str_x315 = "admin"
str_x31d = "Pickles are fun"
tup_x32f = (str_x315, str_x31d)
str_x331 = "proxies"
dict_x33b = {}
...
dict_x51 = {
str_x54: what_x16c,
str_x16d: what_x30d,
str_x30e: tup_x32f,
str_x331: dict_x33b,
str_x33d: dict_x345,
str_x355: dict_x35e,
str_x360: True,
str_x36a: None,
str_x372: what_x5c8,
str_x5c9: False,
str_x5d3: True,
str_x5e0: 30
}
It might be helpful to rename variables for understanding, or run pdP >
/tmp/pickle_source.py to get a .py file to open in your favorite text editor.
In short though, the above code sets up the dictionary dict_x51 where the
auth element is set to the tuple ("admin", "Pickles are fun").
We just stole the admin credentials!
Now I don’t recommend doing this on a real pentest, but let’s take things farther. We can patch the pickle to use our own malicious webserver. We first need to find the current URL, so we search for “https” and find the following code.
str_x5f4 = "baseurl"
str_x5fe = "https://example.com/"
dict_x21 = {str_x24: what_x5f3, str_x5f4: str_x5fe}
what_x616 = api.__new__(g_Api_x1c, *())
So the baseurl of the API is being set to https://example.com/. To patch
this, we seek to where the URL string is created. We can use the x5fe in the
variable name to know where the variable was created, or we can just seek to
the pick.str_x5e flag. When seeking to a flag in r2 you can tab complete the
flag. Notice the prompt changes its location number after the seek command.
[0x00000000]> s pick.str_x5fe
[0x000005fe]> pd 1
;-- pick.str_x5fe:
0x000005fe 8c1468747470. short_binunicode "https://example.com/" ; 0x600
Let’s overwrite this URL with https://doyensec.com/. The below Radare2
commands are commented so you can understand what they are doing.
[0x000005fe]> oo+ # reopen file in read/write mode
[0x000005fe]> pd 3 # double check what next instructions should be
;-- pick.str_x5fe:
0x000005fe 8c1468747470. short_binunicode "https://example.com/" ; 0x600
0x00000614 94 memoize
0x00000615 75 setitems
[0x000005fe]> r+ 1 # add one extra byte to the file, since our new URL is slightly longer
[0x000005fe]> wa short_binunicode "https://doyensec.com/"
INFO: Written 23 byte(s) (short_binunicode "https://doyensec.com/") = wx 8c1568747470733a2f2f646f79656e7365632e636f6d2f @ 0x000005fe
[0x000005fe]> pd 3 # double check we did not clobber an instruction
;-- pick.str_x5fe:
0x000005fe 8c1568747470. short_binunicode "https://doyensec.com/" ; 0x600
0x00000615 94 memoize
;-- pick.what_x616:
0x00000616 75 setitems
[0x000005fe]> pdP @0 |tail # check that the patch worked
str_x5e0: 30
}
what_x5f3 = g_Session_x4c.__new__(g_Session_x4c, *())
what_x5f3.__setstate__(dict_x51)
str_x5f4 = "baseurl"
str_x5fe = "https://doyensec.com/"
dict_x21 = {str_x24: what_x5f3, str_x5f4: str_x5fe}
what_x617 = g_Api_x1c.__new__(g_Api_x1c, *())
what_x617.__setstate__(dict_x21)
return what_x617
Imagine this is just the first of 100 files and you want to patch them all.
Radare2 is easy to script with r2pipe.
Most commands in r2 have a JSON variant by adding a j to the end. In this
case, pdPj will produce an AST in JSON. This is complete with offsets. Using
this you can write a parser that will automatically find the baseurl element
of the returned api object, get the offset and patch it.
JSON can also be helpful without r2pipe. This is because r2 has a bunch of
built-in features for dealing with JSON. For example, we can pretty print JSON
with ~{}, but for this pickle it would produce 1492 lines of JSON. So better
yet, use r2’s internal gron output with
~{=} and grep for what you want.
[0x000005fe]> pdPj @0 ~{=}https
json.stack[0].value[1].args[0].value[0][1].value[1].args[0].value[1][1].value[1].args[0].value[0][1].value[1].args[0].value[10][1].value[0].value = "https";
json.stack[0].value[1].args[0].value[0][1].value[1].args[0].value[8][1].value[1].args[0].value = "https://";
json.stack[0].value[1].args[0].value[1][1].value = "https://doyensec.com/";
Now we can go use the provided JSON path to find the offset of the doyensec.com URL.
[0x00000000]> pdPj @0 ~{stack[0].value[1].args[0].value[1][1].value}
https://doyensec.com/
[0x00000000]> pdPj @0 ~{stack[0].value[1].args[0].value[1][1]}
{"offset":1534,"type":"PY_STR","value":"https://doyensec.com/"}
[0x00000000]> pdPj @0 ~{stack[0].value[1].args[0].value[1][1].offset}
1534
[0x00000000]> s `pdPj @0 ~{stack[0].value[1].args[0].value[1][1].offset}` ## seek to address using subcomand
[0x000005fe]> pd 1
;-- pick.str_x5fe:
0x000005fe 8c1568747470. short_binunicode "https://doyensec.com/" ; 0x600
Don’t forget you can pipe to external commands. For example, pdPj |jq can be used to
search the AST for different patterns. For example, you could return all
objects where the type is PY_GLOBAL.
The r2pickledec plugin simplifies reversing of pickles. Because it is a r2 plugin, you get all the features of r2. We barely scratched the surface of what r2 can do. If you’d like to learn more, check out the r2 book. Be sure to keep an eye out for my next post where I will go into Python pickle obfuscation techniques.
As more companies develop in-house services and tools to moderate access to production environments, the importance of understanding and testing these Zero Touch Production (ZTP) platforms grows 1 2. This blog post aims to provide an overview of ZTP tools and services, explore their security role in DevSecOps, and outline common pitfalls to watch out for when testing them.
“Every change in production must be either made by automation, prevalidated by software or made via audited break-glass mechanism.” – Seth Hettich, Former Production TL, Google
This terminology was popularized by Google’s DevOps teams and is the golden standard to this day. According to this picture, there are SREs, a selected group of engineers that can exclusively use their SSH production access to act when something breaks. But that access introduces reliability and security risks if they make a mistake or their accounts are compromised. To balance this risk, companies should automate the majority of the production operations while providing routes for manual changes when necessary. This is the basic reasoning behind what was introduced by the “Zero Touch Production” pattern.

The “Safe Proxy” model refers to the tools that allow authorized persons to access or modify the state of physical servers, virtual machines, or particular applications. From the original definition:
At Google, we enforce this behavior by restricting the target system to accept only calls from the proxy through a configuration. This configuration specifies which application-layer remote procedure calls (RPCs) can be executed by which client roles through access control lists (ACLs). After checking the access permissions, the proxy sends the request to be executed via the RPC to the target systems. Typically, each target system has an application-layer program that receives the request and executes it directly on the system. The proxy logs all requests and commands issued by the systems it interacts with.
There are various outage scenarios prevented by ZTP (e.g., typos, cut/paste errors, wrong terminals, underestimating blast radius of impacted machines, etc.). On paper, it’s a great way to protect production from human errors affecting the availability, but it can also help to prevent some forms of malicious access. A typical scenario involves an SRE that is compromised or malicious and tries to do what an attacker would do with privileges. This could include bringing down or attacking other machines, compromising secrets, or scraping user data programmatically. This is why testing these services will become more and more important as the attackers will find them valuable and target them.
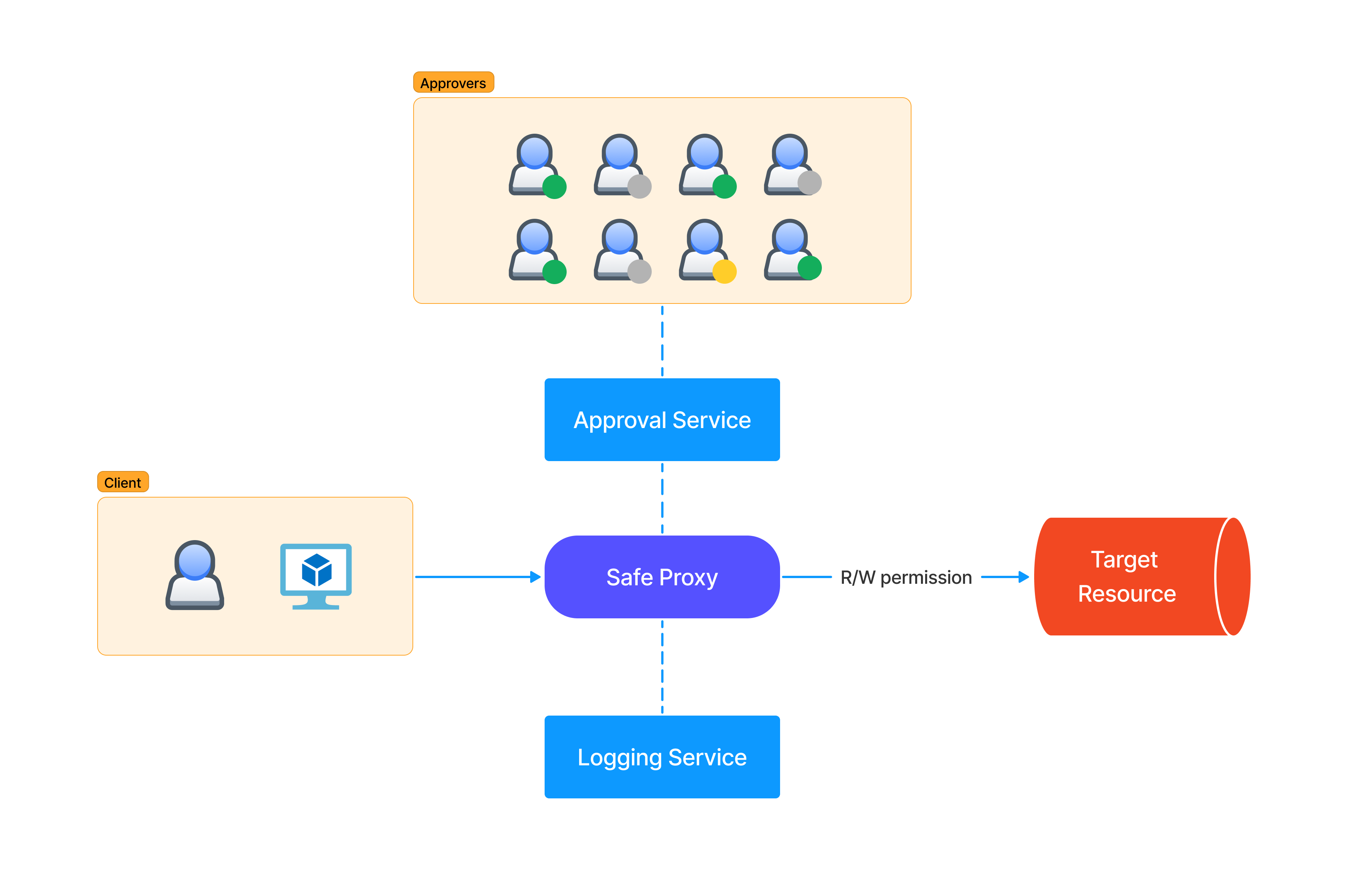
Many companies nowadays need these secure proxy tools to realize their vision, but they are all trying to reinvent the wheel in one way or another. This is because it’s an immature market and no off-the-shelf solutions exist. During the development, the security team is often included in the steering committee but may lack the domain-specific logic to build similar solutions. Another issue is that since usually the main driver is the DevOps team wanting operational safety, availability and integrity are prioritized at the expense of confidentiality. In reality, the ZTP framework development team should collaborate with SRE and security teams throughout the design and implementation phases, ensuring that security and reliability best practices are woven into the fabric of the framework and not just bolted on at the end.
Last but not least, these solutions are to this day suffering in their adoption rates and are subjected to lax intepretations (to a point where developers are the ones using these systems to access what they’re allowed to touch in production). These services are particularly juicy for both pentesters and attackers. It’s not an understatement to say that every actor compromising a box in a corporate environment should first look at these services to escalate their access.
We compiled some of the most common issues we’ve encountered while testing ZTP implementations below:
ZTP services often expose a web-based frontend for various purposes such as monitoring, proposing commands or jobs, and checking command output. These frontends are prime targets for classic web security vulnerabilities like Cross-Site Request Forgery (CSRF), Server-Side Request Forgery (SSRF), Insecure Direct Object References (IDORs), XML External Entity (XXE) attacks, and Cross-Origin Resource Sharing (CORS) misconfigurations. If the frontend is also used for command moderation, it presents an even more interesting attack surface.
Webhooks are widely used in ZTP platforms due to their interaction with team members and on-call engineers. These hooks are crucial for the command approval flow ceremony and for monitoring. Attackers may try to manipulate or suppress any Pagerduty, Slack, or Microsoft Teams bot/hook notifications. Issues to look for include content spoofing, webhook authentication weaknesses, and replay attacks.
Safety checks in ZTP platforms are usually evaluated centrally. A portion of the solution is often hosted independently for availability, to evaluate the rules set by the SRE team. It’s essential to assess the security of the core service, as exploiting or polluting its visibility can affect the entire infrastructure’s availability (what if the service is down? who can access this service?).
In an hypotetical sample attack scenario, if a rule is set to only allow reboots of a certain percentage of the fleet, can an attacker pollute the fleet status and make the hosts look alive? This can be achieved with ping reply spoofing or via MITM in the case of plain HTTP health endpoints. Under these premises, network communications must be Zero Trust too to defend against this.
The templates for the policy configuration managing the access control for services are usually provided to service owners. These can be a source of errors themselves. Users should be guided to make the right choices by providing templates or automatically generating settings that are secure by default. For a full list of the design strategies presented, see the “Building Secure and Reliable Systems” bible 3.
Inconsistent or excessive logging retention of command outputs can be hazardous. Attackers might abuse discrepancies in logging retention to access user data or secrets logged in a given command or its results.
Proper rate-limiting configuration is essential to ensure an attacker cannot change all production “at once” by themselves. The rate limiting configuration should be agreed upon with the team responsible for the mediated services.
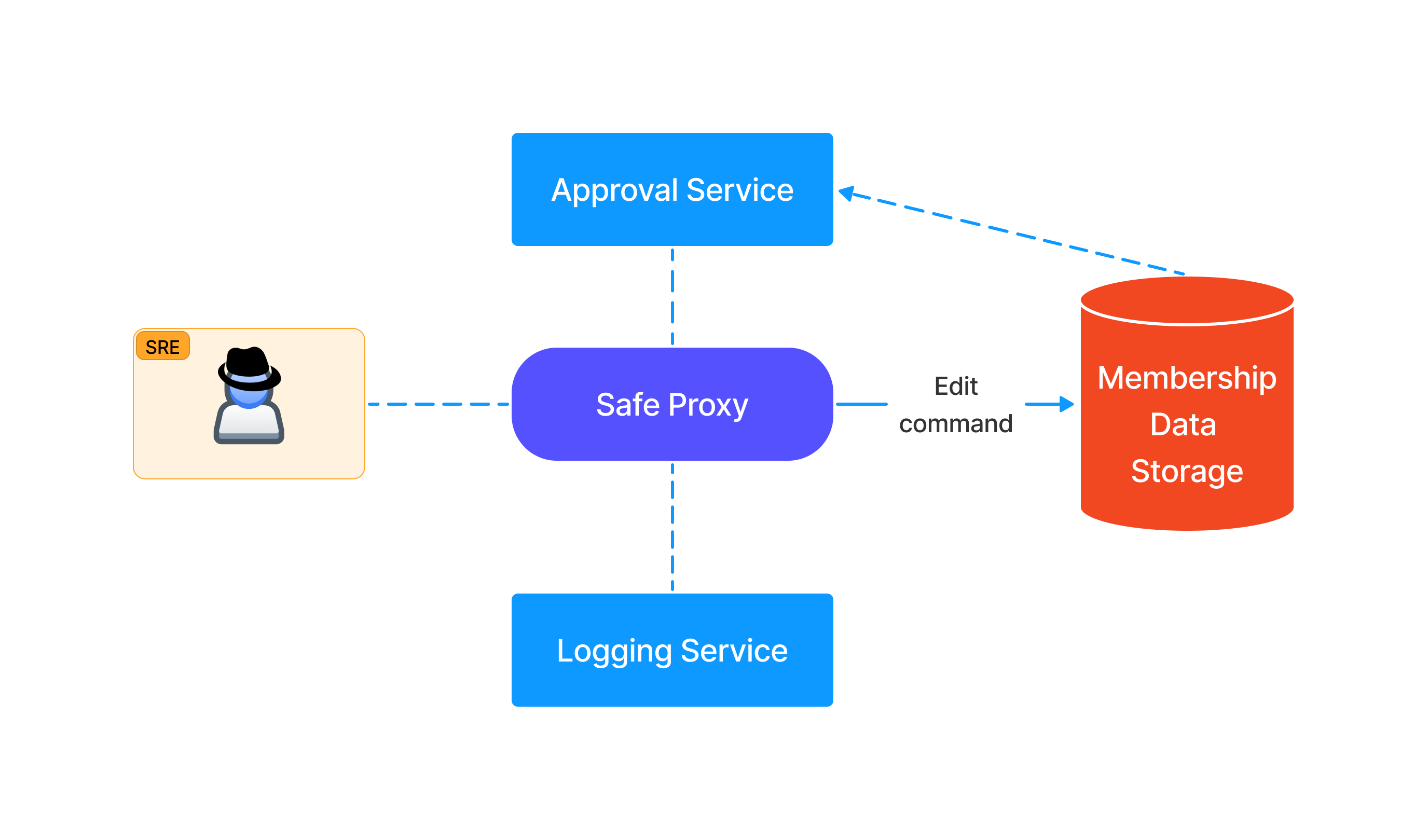
Another pitfall is found in what provides the ownership or permission logic for the services. If SREs can edit membership data via the same ZTP service or via other means, an attacker can do the same and bypass the solution entirely.
Strict allowlists of parameters and configurations should be defined for commands or jobs that can be run. Similar to “living off the land binaries” (lolbins), if arguments to these commands are not properly vetted, there’s an increased risk of abuse.
A reason for the pushed command must always be requested by the user (who, when, what, WHY). Ensuring traceability and scoping in the ZTP platform helps maintain a clear understanding of actions taken and their justifications.
The ZTP platform should have rules in place to detect not only if the user is authorized to access user data, but also which kind and at what scale. Lack of fine-grained authorization or scoping rules for querying user data increases the risk of abuse.
ZTP platforms usually have two types of proxy interfaces: Remote Procedure Call (RPC) and Command Line Interface (CLI). The RPC proxy is used to run CLI on behalf of the user/service in production in a controlled way. Since the implementation varies between the two interfaces, looking for discrepancies in the access requirements or logic is crucial.
The rule evaluation priority (Global over Service-specific) is another area of concern. In general, service rules should not be able to override global rules but only set stricter requirements.
If an allowlist is enforced, inspect how the command is parsed when an allowlist is created (abstract syntax tree (AST), regex, binary match, etc.).
All operations should be queued, and a global queue for the commands should be respected. There should be no chance of race conditions if two concurrent operations are issued.
In the ZTP pattern, a break-glass mechanism is always available for emergency response. Auditing this mode is essential. Entering it must be loud, justified, alert security, and be heavily logged. As an additional security measure, the breakglass mechanism for zero trust networking should be available only from specific locations. These locations are the organization’s panic rooms, specific locations with additional physical access controls to offset the increased trust placed in their connectivity.
As more companies develop and adopt Zero Touch Production platforms, it is crucial to understand and test these services for security vulnerabilities. With an increase in vendors and solutions for Zero Touch Production in the coming years, researching and staying informed about these platforms’ security issues is an excellent opportunity for security professionals.
Michał Czapiński and Rainer Wolafka from Google Switzerland, “Zero Touch Prod: Towards Safer and More Secure Production Environments”. USENIX (2019). Link / Talk ↩
Ward, Rory, and Betsy Beyer. “Beyondcorp: A new approach to enterprise security”, (2014). Link ↩
Adkins, Heather, et al. ““Building secure and reliable systems: best practices for designing, implementing, and maintaining systems”. O’Reilly Media, (2020). Link ↩
A large number of today’s crypto scams involve some sort of phishing attack, where the user is tricked into visiting a shady/malicious web site and connecting their wallet to it. The main goal is to trick the user into signing a transaction which will ultimately give the attacker control over the user’s tokens.
Usually, it all starts with a tweet or a post on some Telegram group or Slack channel, where a link is sent advertising either a new yield farming protocol boasting large APYs, or a new NFT project which just started minting. In order to interact with the web site, the user would need to connect their wallet and perform some confirmation or authorization steps.
Let’s take a look at the common NFT approve scam. The user is lead to the malicious NFT site, advertising a limited pre-mint of their new NFT collection. The user is then prompted to connect their wallet and sign a transaction, confirming the mint. However, for some reason, the transaction fails. The same happens on the next attempt. With each failed attempt, the user becomes more and more frustrated, believing the issue causes them to miss out on the mint. Their concentration and focus shifts slightly from paying attention to the transactions, to missing out on a great opportunity.
At this point, the phishing is in full swing. A few more failed attempts, and the victim bites.
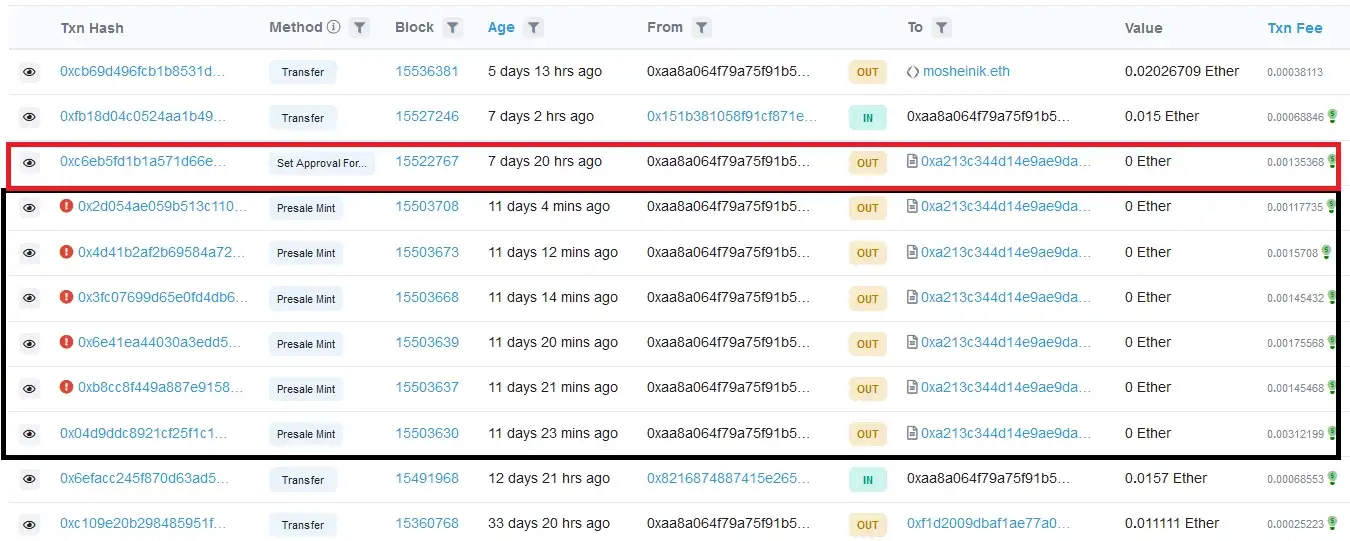
(Image borrowed from How scammers manipulate Smart Contracts to steal and how to avoid it)
The final transaction, instead of the mint function, calls the setApprovalForAll, which essentially will give the malicious actor control over the user’s tokens. The user by this point is in a state where they blindly confirm transactions, hoping that the minting will not close.
Unfortunately, the last transaction is the one that goes through. Game over for the victim. All the attacker has to do now is act quickly and transfer the tokens away from the user’s wallet before the victim realizes what happened.
These type of attacks are really common today. A user stumbles on a link to a project offering new opportunities for profits, they connect their wallet, and mistakenly hand over their tokens to malicious actors. While a case can be made for user education, responsibility, and researching a project before interacting with it, we believe that software also has a big part to play.
Nobody can deny that the introduction of both blockchain-based technologies and Web3 have had a massive impact on the world. A lot of them have offered the following common set of features:
Regardless of the tech-stack used to build these platforms, it’s ultimately the users who make the platform. This means that users need a way to interact with their platform of choice. Today, the most user-friendly way of interacting with blockchain-based platforms is by using a crypto wallet. In simple terms, a crypto wallet is a piece of software which facilitates signing of blockchain transactions using the user’s private key. There are multiple types of wallets including software, hardware, custodial, and non-custodial. For the purposes of this post, we will focus on software based wallets.
Before continuing, let’s take a short detour to Web2. In that world, we can say that platforms (also called services, portals or servers) are primarily built using TCP/IP based technologies. In order for users to be able to interact with them, they use a user-agent, also known as a web browser. With that said, we can make the following parallel to Web3:
| Technology | Communication Protocol | User-Agent |
|---|---|---|
| Web2 | HTTP/TLS | Web Browser |
| Web3 | Blockchain JSON RPC | Crypto Wallet |
Web browsers are arguably much, much more complex pieces of software compared to crypto wallets - and with good reason. As the Internet developed, people figured out how to put different media on it and web pages allowed for dynamic and scriptable content. Over time, advancements in HTML and CSS technologies changed what and how content could be shown on a single page. The Internet became a place where people went to socialize, find entertainment, and make purchases. Browsers needed to evolve, to support new technological advancements, which in turn increased complexity. As with all software, complexity is the enemy, and complexity is where bugs and vulnerabilities are born. Browsers needed to implement controls to help mitigate web-based vulnerabilities such as spoofing, XSS, and DNS rebinding while still helping to facilitate secure communication via encrypted TLS connections.
Next, lets see what a typical crypto wallet interaction for a normal user might look like.
Using a Web3 platform today usually means that a user is interacting with a web application (Dapp), which contains code to interact with the user’s wallet and smart contracts belonging to the platform. The steps in that communication flow generally look like:
In most cases, the user will navigate their web browser to a URL where the Dapp is hosted (ex. Uniswap). This will load the web page containing the Dapp’s code. Once loaded, the Dapp will try to connect to the user’s wallet.
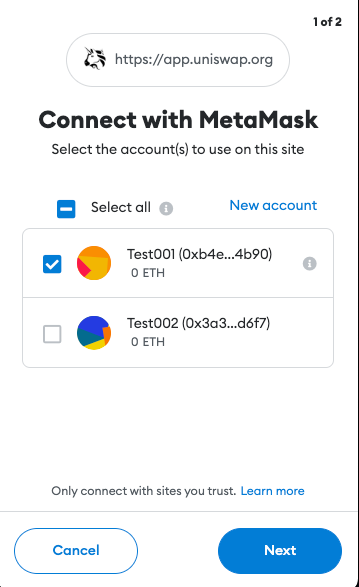
A few of the protections implemented by crypto wallets include requiring authorization before being able to access the user’s accounts and requests for transactions to be signed. This was not the case before EIP-1102. However, implementing these features helped keep users anonymous, stop Dapp spam, and provide a way for the user to manage trusted and un-trusted Dapp domains.
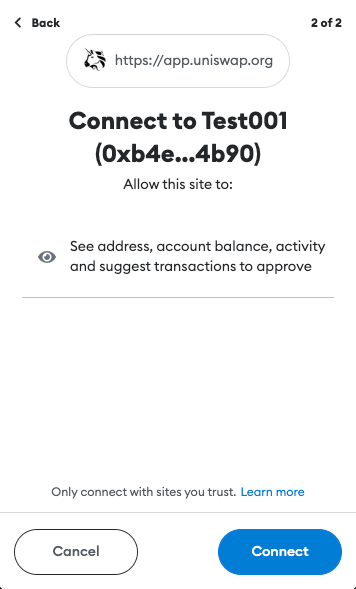
If all the previous steps were completed successfully, the user can start using the Dapp.
When the user decides to perform an action (make a transaction, buy an NFT, stake their tokens, etc.), the user’s wallet will display a popup, asking whether the user confirms the action. The transaction parameters are generated by the Dapp and forwarded to the wallet. If confirmed, the transaction will be signed and published to the blockchain, awaiting confirmation.
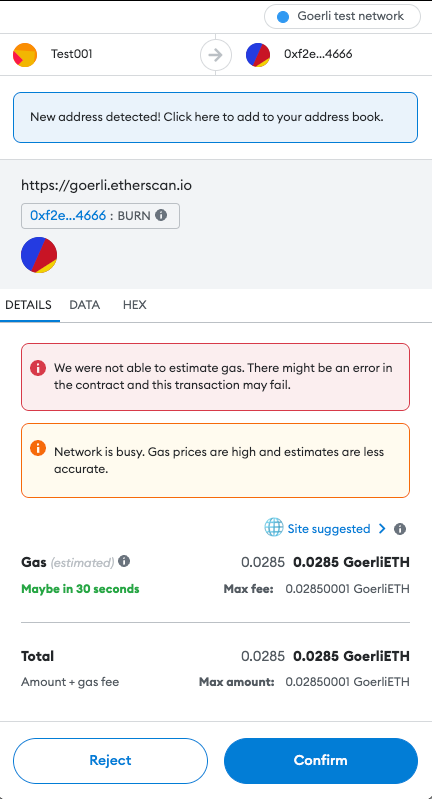
Besides the authorization popup when initially connecting to the Dapp, the user is not shown much additional information about the application or the platform. This ultimately burdens the user with verifying the legitimacy and trustworthiness of the Dapp and, unfortunately, this requires some degree of technical knowledge often out-of-reach for the majority of common users. While doing your own research, a common mantra of the Web3 world, is recommended, one misstep can lead to significant loss of funds.
That being said, let’s now take another detour to Web2 world, and see what a similar interaction looks like.
Like the previous example, we’ll look at what happens when a user wants to use a Web2 application. Let’s say that the user wants to check their email inbox. They’ll start by navigating their browser to the email domain (ex. Gmail). In the background, the browser performs a TLS handshake, trying to establish a secure connection to Gmail’s servers. This will enable an encrypted channel between the user’s browser and Gmail’s servers, eliminating the possibility of any eavesdropping. If the handshake is successful, an encrypted connection is established and communicated to the user through the browser’s UI.

The secure connection is based on certificates issued for the domain the user is trying to access. A certificate contains a public key used to establish the encrypted connection. Additionally, certificates must be signed by a trusted third-party called a Certificate Authority (CA), giving the issued certificate legitimacy and guaranteeing that it belongs to the domain being accessed.
But, what happens if that is not the case? What happens when the certificate is for some reason rejected by the browser? Well, in that case a massive red warning is shown, explaining what happened to the user.
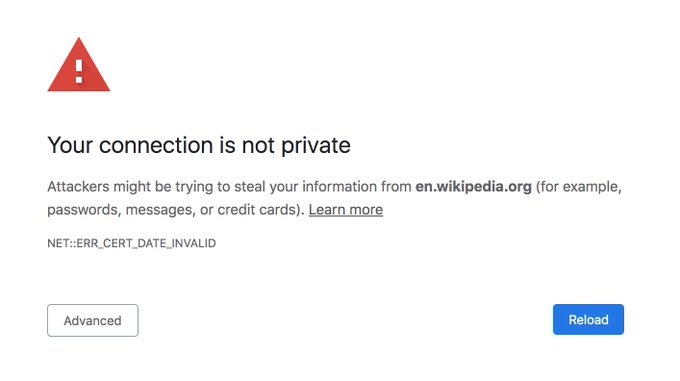
Such warnings will be shown when a secure connection could not be established, the certificate of the host is not trusted or if the certificate is expired. The browser also tries to show, in a human-readable manner, as much useful information about the error as possible. At this point, it’s the choice of the user whether they trust the site and want to continue interacting with it. The task of the browser is to inform the user of potential issues.
Crypto wallets should show the user as much information about the action being performed as possible. The user should see information about the domain/Dapp they are interacting with. Details about the actual transaction’s content, such as what function is being invoked and its parameters should be displayed in a user-readable fashion.
Comparing both previous examples, we can notice a lack of verification and information being displayed in crypto wallets today. This, then poses the question: what can be done? There exist a number of publicly available indicators for the health and legitimacy of a project. We believe communicating these to the user may be a good step forward in addressing this issue. Let’s go quickly go through them.
It is important to prove that a domain has ownership over the smart contracts with which it interacts. Currently, this mechanism doesn’t seem to exist. However, we think we have a good solution. Similarly to how Apple performs merchant domain verification, a simple JSON file or dapp_file can be used to verify ownership. The file can be stored on the root of the Dapp’s domain, on the path .well-known/dapp_file. The JSON file can contain the following information:
At this point, a reader might say: “How does this show ownership of the contract?”. The key to that is the signature. Namely, the signature is generated by using the private key of the account which deployed the contract. The transparency of the blockchain can be used to get the deployer address, which can then be used to verify the signature (similarly to how Ethereum smart contracts verify signatures on-chain).
This mechanism enables creating an explicit association between a smart contract and the Dapp. The association can later be used to perform additional verification.
When a new domain is purchased or registered, a public record is created in a public registrar, indicating the domain is owned by someone and is no longer available for purchase. The domain name is used by the Domain Name Service, or DNS, which translates it (ex www.doyensec.com) to a machine-friendly IP address (ex. 34.210.62.107).
The creation date of a DNS record shows when the Dapp’s domain was initially purchased. So, if a user is trying to interact with an already long established project and runs into a domain which claims to be that project with a recently created domain registration record, it may be a signal of possible fraudulent activities.
Creation and expiration dates of TLS certificates can be viewed in a similar fashion as DNS records. However, due to the short duration of certificates issued by services such as Let’s Encrypt, there is a strong chance that visitors of the Dapp will be shown a relatively new certificate.
TLS certificates, however, can be viewed as a way of verifying a correct web site setup where the owner took additional steps to allow secure communication between the user and their application.
Published and verified source code allows for audits of the smart contract’s functionality and can allow quick identification of malicious activity.
The smart contract’s deployment date can provide additional information about the project. For example, if attackers set up a fake Uniswap web site, the likelihood of the malicious smart contract being recently deployed is high. If interacting with an already established, legitimate project, such a discrepancy should alarm the user of potential malicious activity.
Trustworthiness of a project can be seen as a function of the number of interactions with that project’s smart contracts. A healthy project, with a large user base will likely have a large number of unique interactions with the project’s contracts. A small number of interactions, unique or not, suggest the opposite. While typical of a new project, it can also be an indicator of smart contracts set up to impersonate a legitimate project. Such smart contracts will not have the large user base of the original project, and thus the number of interactions with the project will be low.
Overall, a large number of unique interactions over a long period of time with a smart contract may be a powerful indicator of a project’s health and the health of its ecosystem.
While there are authorization steps implemented when a wallet is connecting to an unknown domain, we think there is space for improvement. The connection and transaction signing process can be further updated to show user-readable information about the domain/Dapp being accessed.
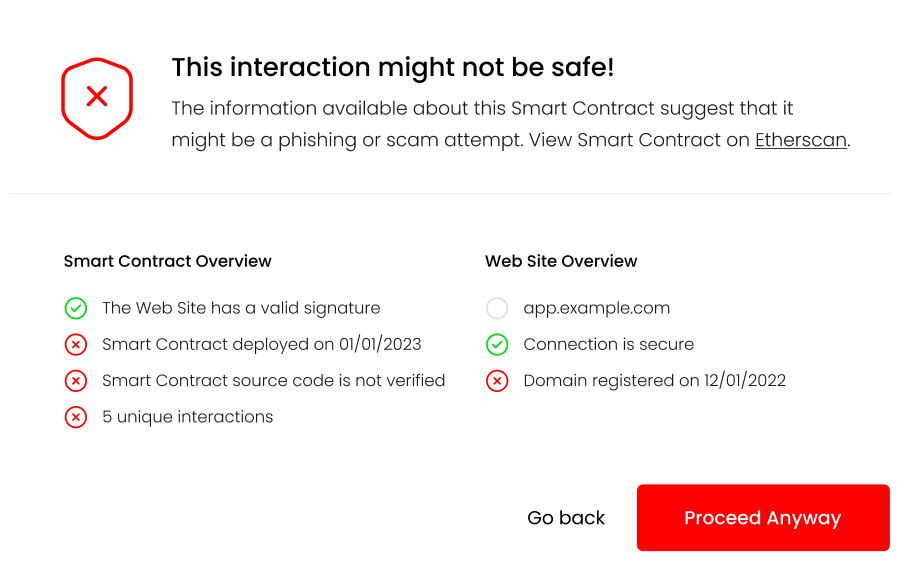
As a proof-of-concept, we implemented a simple web service https://github.com/doyensec/wallet-info. The service utilizes public information, such as domain registration records, TLS certificate information and data available via Etherscan’s API. The data is retrieved, validated, parsed and returned to the caller.
The service provides access to the following endpoints:
/host?url=<url>/contract?address=<address>The data these endpoints return can be integrated in crypto wallets at two points in the user’s interaction.
The /host endpoint can be used when the user is initially connecting to a Dapp. The Dapp’s URL should be passed as a parameter to the endpoint. The service will use the supplied URL to gather information about the web site and its configuration. Additionally, the service will check for the presence of the dapp_file on the site’s root and verify its signature. Once processing is finished, the service will respond with:
{
"name": "Example Dapp",
"timestamp": "2000-01-01T00:00:00Z",
"domain": "app.example.com",
"tls": true,
"tls_issued_on": "2022-01-01T00:00:00Z",
"tls_expires_on": "2022-01-01TT00:00:00Z",
"dns_record_created": "2012-01-01T00:00:00Z",
"dns_record_updated": "2022-08-14T00:01:31Z",
"dns_record_expires": "2023-08-13T00:00:00Z",
"dapp_file": true,
"valid_signature": true
}
This information can be shown to the user in a dialog UI element, such as:

As a concrete example, lets take a look at this fake Uniswap site was active during the writing of this post. If a user tried to connect their wallet to the Dapp running on the site, the following information would be returned to the user:
{
"name": null,
"timestamp": null,
"domain": "apply-uniswap.com",
"tls": true,
"tls_issued_on": "2023-02-06T22:37:19Z",
"tls_expires_on": "2023-05-07T22:37:18Z",
"dns_record_created": "2023-02-06T23:31:09Z",
"dns_record_updated": "2023-02-06T23:31:10Z",
"dns_record_expires": "2024-02-06T23:31:09Z",
"dapp_file": false,
"valid_signature": false
}
The missing information from the response reflect that the dapp_file was not found on this domain. This information will then be reflected on the UI, informing the user of potential issues with the Dapp:
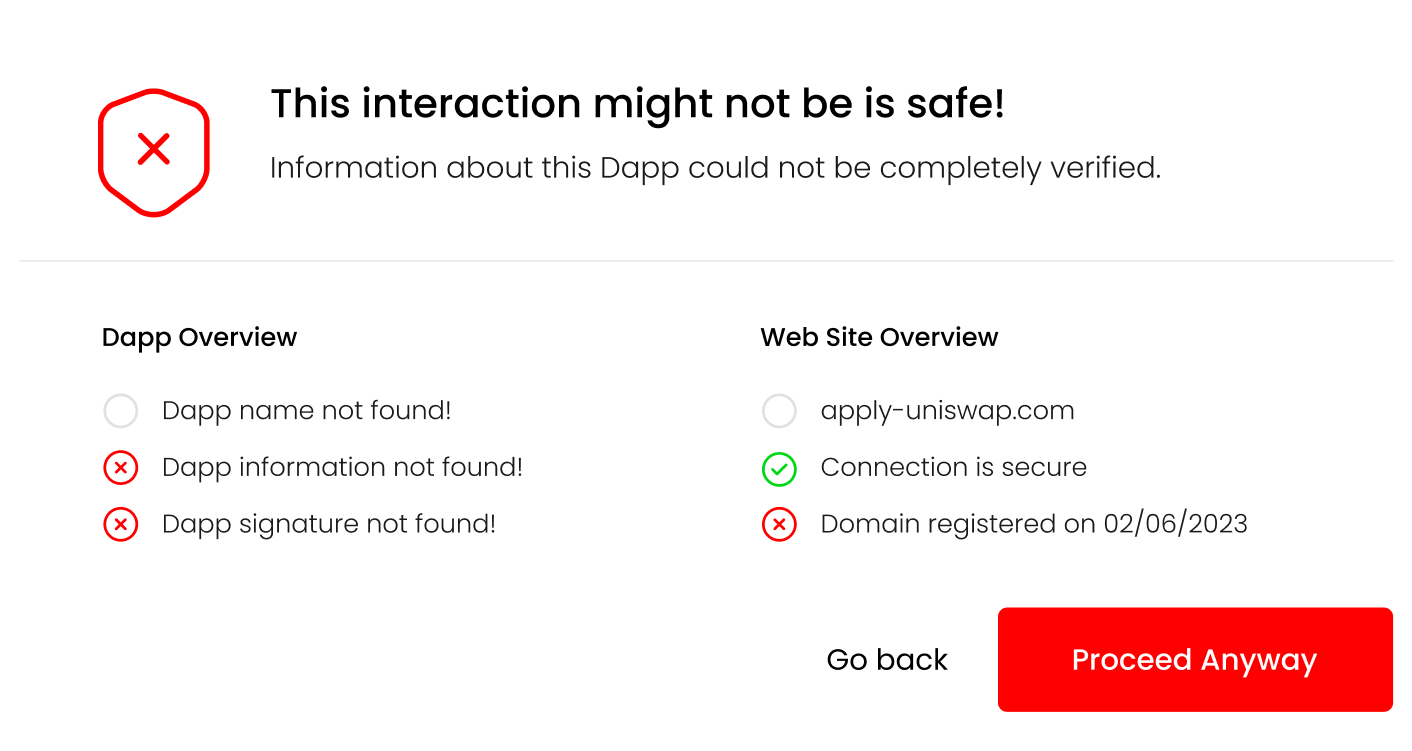
At this point, the users can review the information and decide whether they feel comfortable giving the Dapp access to their wallet. Once the Dapp is authorized, this information doesn’t need to be shown anymore. Though, it would be beneficial to occasionally re-display this information, so that any changes in the Dapp or its domain will be communicated to the user.
Transactions can be split in two groups: transactions that transfer native tokens and transactions which are smart contract function calls. Based on the type of transaction being performed, the /contract endpoint can be used to retrieve information about the recipient of the transferred assets.
For our case, the smart contract function calls are the more interesting group of transactions. The wallet can retrieve information about both the smart contract on which the function will be called as well as the function parameter representing the recipient. For example the spender parameter in the approve(address spender, uint256 amount) function call. This information can be retrieved on a case-by-case basis, depending on the function call being performed.
Signatures of widely used functions are available and can be implemented in the wallet as a type of an allow or safe list. If a signature is unknown, the user should be informed about it.
Verifying the recipient gives users confidence they are transferring tokens, or allowing access to their tokens for known, legitimate addresses.
An example response for a given address will look something like:
{
"is_contract": true,
"contract_address": "0xF4134146AF2d511Dd5EA8cDB1C4AC88C57D60404",
"contract_deployer": "0x002362c343061fef2b99d1a8f7c6aeafe54061af",
"contract_deployed_on": "2023-01-01T00:00:00Z",
"contract_tx_count": 10,
"contract_unique_tx": 5,
"valid_signature": true,
"verified_source": false
}
In the background, the web service will gather information about the type of address (EOA or smart contract), code verification status, address interaction information etc. All of that should be shown to the user as part of the transaction confirmation step.
Links to the smart contract and any additional information can be provided here, helping users perform additional verification if they so wish.
In the case of native token transfers, the majority of verification consists of typing in the valid to address. This is not a task that is well suited for automatic verification. For this use case, wallets provide an “address book” like functionality, which should be utilized to minimize any user errors when initializing a transaction.
The point of this post is to highlight the shortcomings of today’s crypto wallet implementations, to present ideas, and make suggestions for how they can be improved. This field is actively being worked on. Recently, MetaMask updated their confirmation UI to display additional information, informing users of potential setApprovalForAll scams. This is a step in the right direction, but there is still a long way to go. Features like these can be built upon and augmented, to a point where users can make transactions and know, to a high level of certainty, that they are not making a mistake or being scammed.
There are also third-party groups like WalletGuard and ZenGo who have implemented similar verifications described in this post. These features should be a standard and required for every crypto wallet, and not just an additional piece of software that needs to be installed.
Like the user-agent of Web2, the web browser, user-agents of Web3 should do as much as possible to inform and protect their users.
Our implementation of the wallet-info web service is just an example of how public information can be pooled together. That information, combined with a good UI/UX design, will greatly improve the security of crypto wallets and, in turn, the security of the entire Web3 ecosystem.
Does Dapp verification completely solve the phishing/scam problem? Unfortunately, the answer is no. The proposed changes can help users in distinguishing between legitimate projects and potential scams, and guide them to make the right decision. Dedicated attackers, given enough time and funds, will always be able to produce a smart contract, Dapp or web site, which will look harmless using the indicators described above. This is true for both the Web2 and Web3 world.
Ultimately, it is up to the user to decide if the they feel comfortable giving their login credentials to a web site, or access to their crypto wallet to a Dapp. All software can do is point them in the right direction.