ABOUT US
We are security engineers who break bits and tell stories.
Visit us
doyensec.com
Follow us
@doyensec
Engage us
info@doyensec.com
Blog Archive
© 2026 Doyensec LLC 
Recently, a client of ours asked us to put R2c’s Semgrep in a head-to-head test with GitHub’s CodeQL. Semgrep is open source and free (with premium options). CodeQL “is free for research and open source” projects and accepts open source contributions to its libraries and queries, but is not free for most companies. Many of our engineers had already been using Semgrep frequently, so we were reasonably familiar with it. On the other hand, CodeQL hadn’t gained much traction for our internal purposes given the strict licensing around consulting. That said, our client’s use case is not the same as ours, so what works for us, may not work well for them. We have decided to share our results here.
A SAST tool generally consists of a few components 1) a lexer/parser to make sense of the language, 2) rules which process the output produced by the lexer/parser to find vulnerabilities and 3) tools to manage the output from the rules (tracking/ticketing, vulnerability classification, explanation text, prioritization, scheduling, third-party integrations, etc).
The rules are usually the source of most SAST complaints because ultimately, we all hope ideally that the tool produces perfect results, but that’s unrealistic. On one hand, you might get a tool that doesn’t find the bug you know is in the code (a false negative - FN) or on the other, it might return a bunch of useless supposed findings that are either lacking any real impact or potentially just plain wrong (a false positive - FP). This leads to our first issue when attempting to quantitatively measure how good a SAST tool is - what defines true/false or positives/negatives?
Some engineers might say a true positive is a demonstrably exploitable condition, while others would say matching the vulnerable pattern is all that matters, regardless of the broader context. Things are even more complicated for applications that incorporate vulnerable code patterns by design. For example, systems administration applications which executes shell commands, via parameters passed in a web request. In most environments, this is the worst possible scenario. However, for these types of apps, it’s their primary purpose. In those cases, engineers are then left with the subjective question of whether to classify a finding as a true or false positive where an application’s users can execute arbitrary code in an application, that they’d need to be fully and properly authenticated and authorized to do.
These types of issues come from asking too much of the SAST application and we should focus on locating vulnerable code patterns - leaving it to people to vet and sort the findings. This is one of the places where the third set of components comes into play and can be a real differentiator between SAST applications. How users can ignore the same finding class(es), findings on the same code, findings on certain paths, or conditionally ignoring things, becomes very important to filter the signal from the noise. Typically, these tools become more useful for organizations that are willing to commit the time to configure the scans properly and refine the results, rather than spending it triaging a bunch of issues they didn’t want to see in the first place and becoming frustrated.
Furthermore, quantitative comparisons between tools can be problematic for several reasons. For example, if tool A finds numerous low severity bugs, but misses a high severity one, while tool B finds only a high severity bug, but misses all the low severity ones, which is a better tool? Numerically, tool A would score better, but most organizations would rather find the higher severity vulnerability. If tool A finds one high severity vulnerability and B finds a different one, but not the one A finds, what does it mean? Some of these questions can be handled with statistical methods, but most people don’t usually take this approach. Additionally, issues can come up when you’re in a multi-language environment where a tool works great on one language and not so great on the others. Yet another twist might be if a tool missed a vulnerability that was due to a parsing error, that would certainly be fixed in a later release, rather than a rules matching issue specifically.
These types of concerns don’t necessarily have easy answers and it’s important to remember that any evaluation of a SAST tool is subject to variations based on the language(s) being examined, which rules are configured to run, the code repository’s structure and contents, and any customizations applied to the rules or tool configuration.
Another hurdle in properly evaluating a SAST tool is finding a body of code on which to test it. If the objective is to simply scan the code and verify whether the findings are true positives (TP) or false positives (FP), virtually any supported code could work, but finding true negatives (TN) and false negatives (FN) require prior knowledge of the security state of the code or having the code manually reviewed.
This then raises the question of how to quantify the negatives that a SAST tool can realistically discover. Broadly, a true positive is either a connection of a source and unprotected sink or possibly a stand-alone configuration (e.g., disabling a security feature). So how do we count true negatives specifically? Do we count the total number or sources that lead to a protected sink, the total of protected sinks, the total safe function calls (regardless if they are identified sinks), and all the safe configuration options? Of course, if the objective is solely to verify the relative quality of detection between competing software, simply comparing the results, provided all things were reasonably equal, can be sufficient.

We utilized the OWASP Benchmark Project to analyze pre-classified Java application code to provide a more accurate head-to-head comparison of Semgrep vs. CodeQL. While we encountered a few bugs running the tools, we were able to work around them and produce a working test and meaningful results.
Both CodeQL and Semgrep came with sample code used to demonstrate the tool’s capabilities. We used the test suite of sample vulnerabilities from each tool to test the other, swapping the tested files “cross-tool”. This was done with the assumption that the test suite for each tool should return 100% accurate results for the original tool, by design, but not necessarily for the other. Some modifications and omissions were necessary however, due to the organization and structure of the test files.
We also ran the tools against a version of our client’s code in the manner that required the least amount of configuration and/or knowledge of the tools. This was intended to show what you get “out of the box” for each tool. We iterated over several configurations of the tools and their rules, until we came to a meaningful, yet manageable set of results (due to time constraints).
When comparing SAST tools, based on past experience, we feel these criteria are important aspects that need to be examined.
The images below outline the supported languages for each tool, refer to the source links for additional information about the supported frameworks:
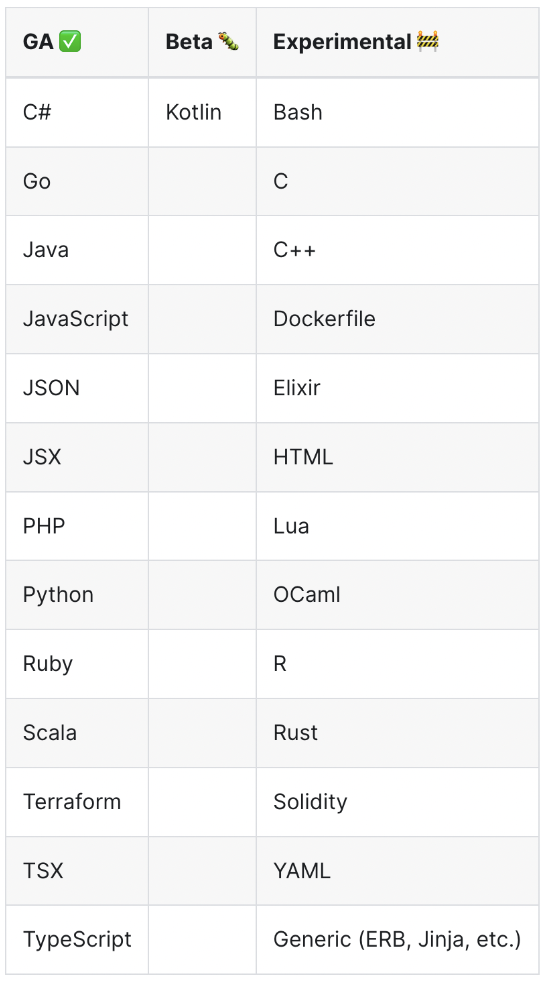
Source: https://semgrep.dev/docs/supported-languages/
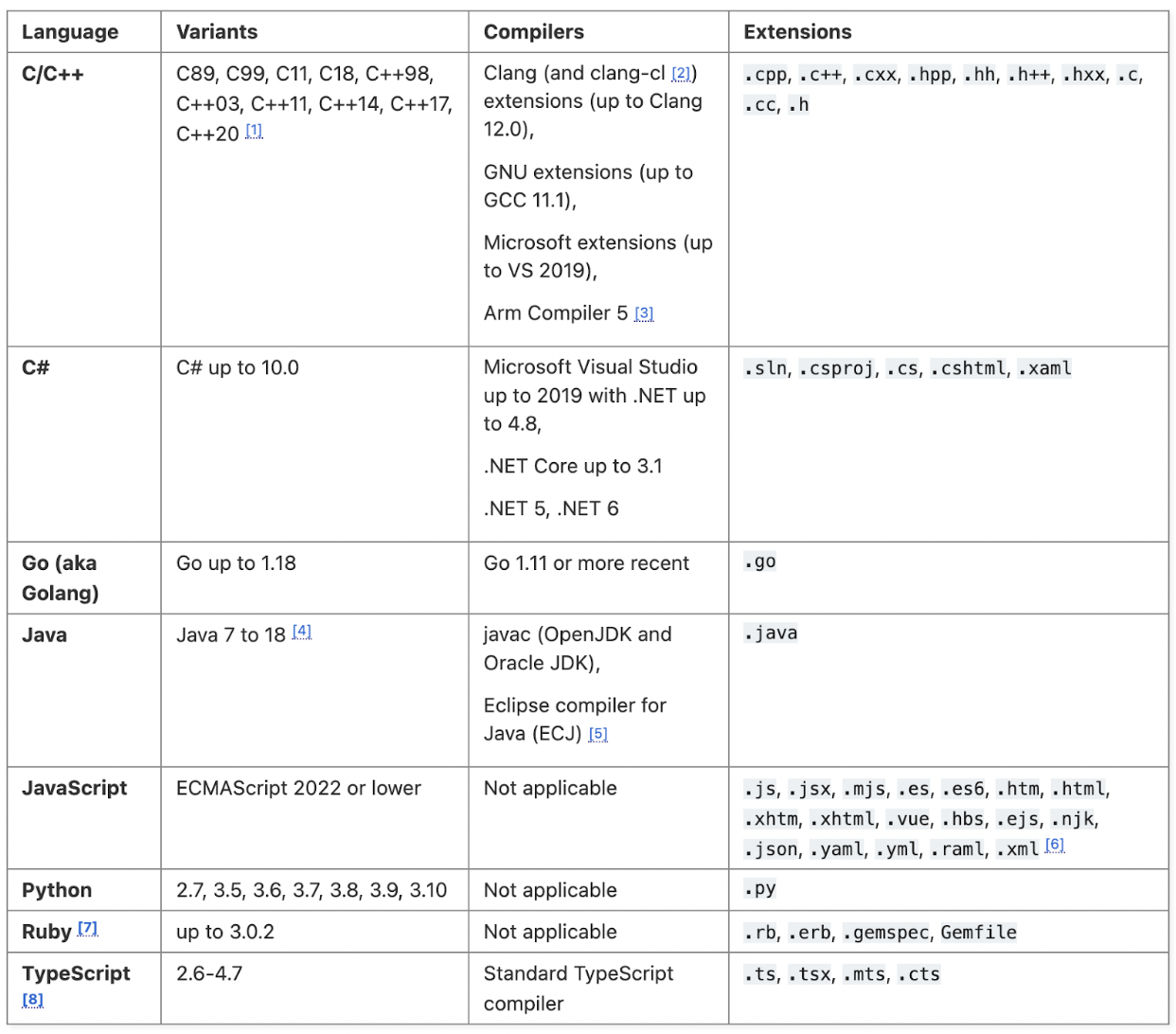
Source: https://codeql.github.com/docs/codeql-overview/supported-languages-and-frameworks/
Not surprisingly, we see support for many of the most popular languages in both tools, but a larger number, both in GA and under development in Semgrep. Generally speaking, this gives an edge to Semgrep, but practically speaking, most organizations only care if it supports the language(s) they need to scan.
Lexer/parser performance will vary based on the language and framework, their versions and code complexity. It is only possible to get a general sense of this by scanning numerous repositories and monitoring for errors or examining the source of the parser and tool.
During testing on various applications, both tools encountered errors allowing only the partial parsing of many files. The thoroughness of the parsing results varied depending on the tool and on the code being analyzed. Testing our client’s Golang project, we did occasionally encounter parsing errors with both as well.
We encountered an issue when testing against third-party code where a custom function (exit()) was declared and used, despite being reserved, causing the parser to fail once the function was reached, due to invalid syntax. The two notable things here are that the code should theoretically not work properly and that despite this, Semgrep was still able to perform a partial examination. Semgrep excelled in terms of the ability to handle incomplete code or code with errors as it operates on a single file scope generally.
CodeQL works a bit differently, in that it effectively creates a database from the code, allowing you to then write queries against that database to locate vulnerabilities. In order for it to do this, it requires a fully buildable application. This inherently means that it must be more strict with its ability to parse all the code.
In our testing, CodeQL generated errors on the majority of files that it had findings for (partial parsing at best), and almost none were analyzed without errors. Roughly 85% of files generated some errors during database creation.
According to CodeQL, a small number of extraction errors is normal, but a large number is not. It was unclear how to reduce the large number of extraction errors. According to CodeQL’s documentation, the only ways were to wait for CodeQL to release a fixed version of the extractor or to debug using the logs. We attempted to debug with the logs, but the error messages were not completely clear and it seemed that the two most common errors were related to the package names declared at the top of the files and variables being re-declared. It was not completely clear if these errors were due to an overly strict extractor or if the code being tested was incomplete.
Semgrep would seem to have the advantage here, but it’s not a completely fair comparison, due to the different modes of operation.
Among the options you can select when firing up a Semgrep scan are:
Notes:
While the tool does provide an automated scanning option, we found situations in which -–config auto did not find all the vulnerabilities that manually selecting the language did.
The re-use/tracking of the scan results requires using Semgrep CI or Semgrep App.
CodeQL requires a buildable application (i.e., no processing of a limited set of files), with a completely different concept of “scanning”, so this notion doesn’t directly translate. In effect, you create a database from the code, which you subsequently query to find bugs, so much of the “filtering” can be accomplished by modifying the queries that are run.
Options include:
Because CodeQL creates a searchable database, you can indefinitely run queries against the scanned version of the code.
Because of the different approaches it is difficult to say one tool has an advantage over the other. The most significant difference is probably that Semgrep allows you to automatically fix vulnerabilities.
As mentioned previously, these tools take completely different approaches (i.e., rules vs queries). Whether someone prefers writing queries vs. YAML is subjective, so we’ll not discuss the formats themselves specifically.
As primarily a string-matching static code analysis tool, Semgrep’s accuracy is mostly driven by the rules in use and their modes of operation. Semgrep is probably best thought of as an improvement on the Linux command line tool grep. It adds improved ease of use, multi-line support, metavariables and taint tracking, as well as other features that grep directly does not support. Beta features also include the ability to track across related files.
Semgrep rules are defined in relatively simple YAML files with only a handful of elements used to create them. This allows someone to become reasonably proficient with the tool in a matter of hours, after reading the documentation and tutorials. At times, the tool’s less than full comprehension of the code can cause rule writing to be more difficult than it might appear at first glance.
In Semgrep, there are several ways to execute rules, either locally or remotely. Additionally, you can pass them as command line arguments referred to as “ephemeral” rules, eliminating the YAML files altogether.
The rule below shows an example of a reasonably straightforward rule. It effectively looks for an insecure comparison of something that might be a secret within an HTTP request.
rules:
- id: insecure-comparison-taint
message: >-
User input appears to be compared in an insecure manner that allows for side-channel timing attacks.
severity: ERROR
languages: [go]
metadata:
category: security
mode: taint
pattern-sources:
- pattern-either:
- pattern: "($ANY : *http.Request)"
- pattern: "($ANY : http.Request)"
pattern-sinks:
- patterns:
- pattern-either:
- pattern: "... == $SECRET"
- pattern: "... != $SECRET"
- pattern: "$SECRET == ..."
- pattern: "$SECRET != ..."
- pattern-not: len(...) == $NUM
#- pattern-not: <... len(...) ...>
- metavariable-regex:
metavariable: $SECRET
regex: .*(secret|password|token|otp|key|signature|nonce).*
The logic in the rules is familiar and amounts to what feels like stacking of RegExs, but with the added capability of creating boundaries around what is matched against and with the benefit of language comprehension. It is important to note however that Semgrep lacks a full understanding of the code flow sufficient enough to trace source to sink flows through complex code. By default it works on a single file basis, but Beta features also include the ability to track across related files. Semgrep’s current capabilities lie somewhere between basic grep and a traditional static code analysis tool, with abstract syntax trees and control flow graphs.
No special preparation of repositories is needed before scanning can begin. The tool is fully capable of detecting languages and running simultaneous scans of multiple languages in heterogeneous code repositories. Furthermore, the tool is capable of running on code which isn’t buildable, but the tool will return errors when it parses what it deems as invalid syntax.
That said, rules tend to be more general than the queries in CodeQL and could potentially lead to more false positives. For some situations, it is not possible to make a rule that is completely accurate without customizing the rule to match a specific code base.
CodeQL’s query language has a SQL-like syntax with the following features:
The engine has extractors for each supported language. They are used to extract the information from the codebase into the database. Multi-language code bases are analyzed one at a time. Trying to specify a list of target languages (go, javascript and c) didn’t work out of the box because CodeQL required to explicitly set the build command for this combination of languages.
CodeQL can also be used in VSCode as an extension, a CLI tool or integrated with Github workflows. The VS extension code allows writing the queries with the support of the autocompletion by the IDE and testing them against one or more databases previously created.
The query below shows how you would search for the same vulnerability as the Semgrep rule above.
/**
* @name Insecure time comparison for sensitive information
* @description Input appears to be compared in an insecure manner (timing attacks)
*/
import go
from EqualityTestExpr e, DataFlow::CallNode called
where
// all the functions call where the argument matches the RegEx
called
.getAnArgument()
.toString()
.toLowerCase()
.regexpMatch(".*(secret|password|token|otp|key|signature|nonce).*") and
e.getAnOperand() = called.getExpr()
select called.getExpr(), "Uses a constant time comparison for sensitive information"
In order to create a database, CodeQL requires a buildable codebase. This means that an analysis consists of multiple steps: standard building of the codebase, creating the database and querying the codebase. Due to the complexity of the process in every step, our experience was that a full analysis can require a non-negligible amount of time in some cases.
Writing queries for CodeQL also requires a great amount of effort, especially at the beginning. The user should know the CodeQL syntax very well and pay attention to the structure of the condition to avoid killing the performance. We experienced an infinite compilation time just adding an OR condition in the WHERE clause of a query. Starting from zero experience with the tool, the benefits of using CodeQL are perceivable only in the long run.
As Semgrep allows you to output to a number of formats, along with the CLI output, there are a number of ways you can manage the findings. They also list some of this information on their manage-findings page.
Because the CodeQL CLI tool reports findings in a CSV or SARIF file format, triaging findings reported by it can be quite tedious. During testing, we felt the easiest way to review findings from the CodeQL CLI tool was to launch the query from Visual Studio Code and manually review the results from there (due to the IDE’s navigation features). Ultimately, in real-world usage, the results are probably best consumed through the integration with GitHub.
Due to the differences between their approaches, it’s difficult to fairly quantify the differences in speed between the two tools. Semgrep is a clear winner in the time it takes to setup, run a scan and get results. It doesn’t interpret the code as deeply as CodeQL does, nor does it have to create a persistent searchable database, then run queries against it. However, once the database is created, you could argue that querying for a specific bug in CodeQL versus scanning a project again in Semgrep would be roughly similar, depending on multiple factors not directly related to the tools (e.g., hardware, language, code complexity).
This highlights the fact that tool selection criteria should incorporate the use-case.
This section shows the results of using both of these SAST tools to test the same repository of Java code (the only language option). This project’s sample code had been previously reviewed and categorized, specifically to allow for benchmarking of SAST tools. Using this approach we could relatively easily run a head-to-head comparison and allow the OWASP Benchmark Project to score and graph the performance of each tool.
Drawbacks to this approach include the fact that it is one language, Java, and that is not the language of choice for our client. Additionally, SAST tool maintainers, who might be aware of this project, could theoretically ensure their tools perform well in these tests specifically, potentially masking shortcomings when used in broader contexts.
In this test, Semgrep was configured to run with the latest “security-audit” Registry ruleset, per the OWASP Benchmark Project recommendations. CodeQL was run using the “Security-and-quality queries” query suite. The CodeQL query suite includes queries from “security-extended”, plus maintainability and reliability queries.
As you can see from the charts below, Semgrep performed better, on average, than CodeQL did. Examining the rules a bit more closely, we see three CWE (Common Weakness Enumeration) areas where CodeQL does not appear to find any issues, significantly impacting the average performance. It should also be noted that CodeQL does outperform in some categories, but determining the per-category importance is left to the tool’s users.
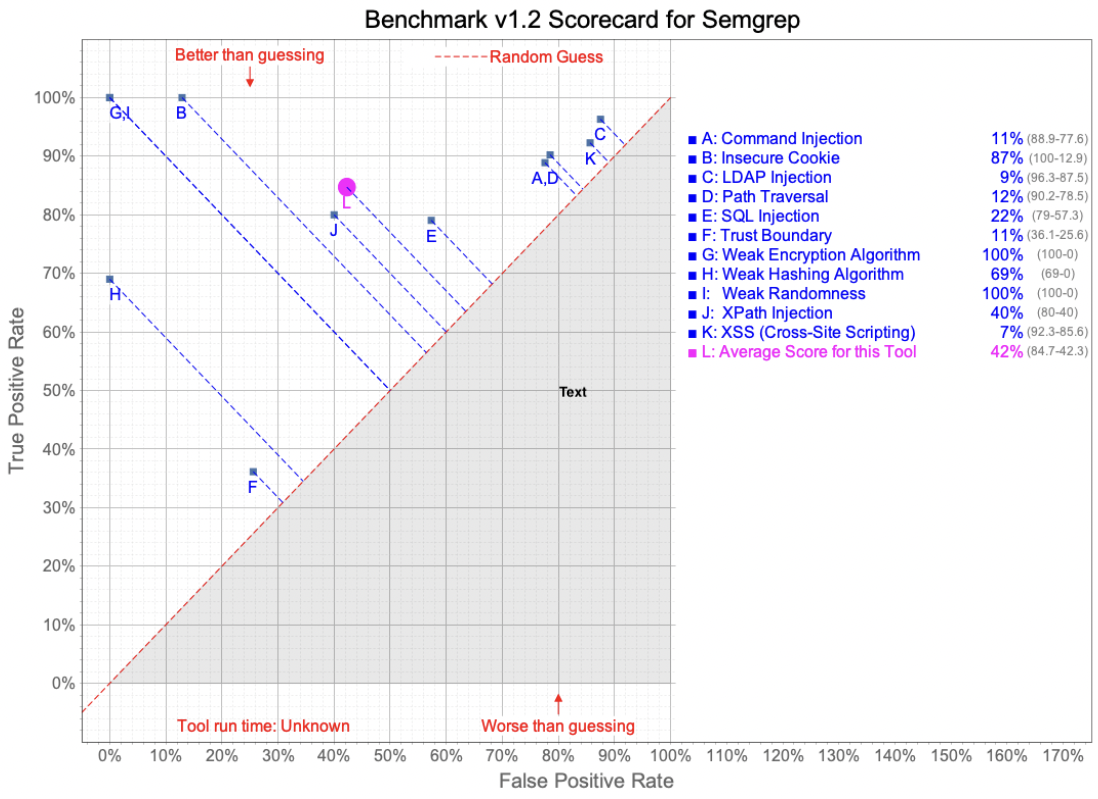
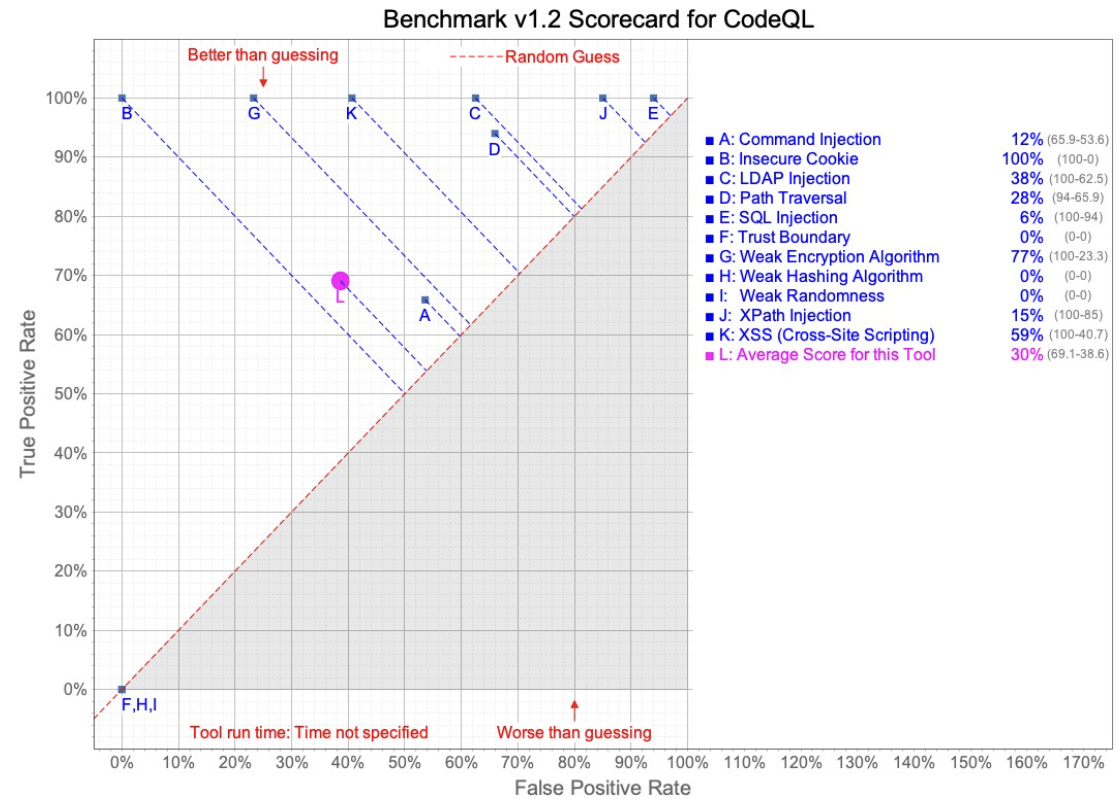
This section discusses the results of using the Semgrep tool against the test cases for CodeQL and vice versa. While initially seeming like a great way to compare the tools, unfortunately, the test case files presented several challenges to this approach. While being labeled things like “Good” and “Bad” either in file names or comments, the files were not necessarily all “Good” code or “Bad” code, but inconsistently mixed, inconsistently labeled and sometimes with multiple potential vulnerabilities in the same files. Additionally, we occasionally discovered vulnerabilities in some of the files which were not the CWE classes that were supposed to be in the files (e.g., finding XSS in an SQL Injection test case).
These issues prevented a simple count based on the files that were/were not found to have vulnerabilities. The statistics we present have been modified as much as possible in the allotted time to account for these issues and we have applied data analysis techniques to account for some of the errors.
As you can see in the table below, CodeQL performed significantly better with regards to detection, but at the cost of a higher false positive rate as well. This underscores some of the potential tradeoffs, mentioned in the introduction, which need to be considered by the consumer of the output.
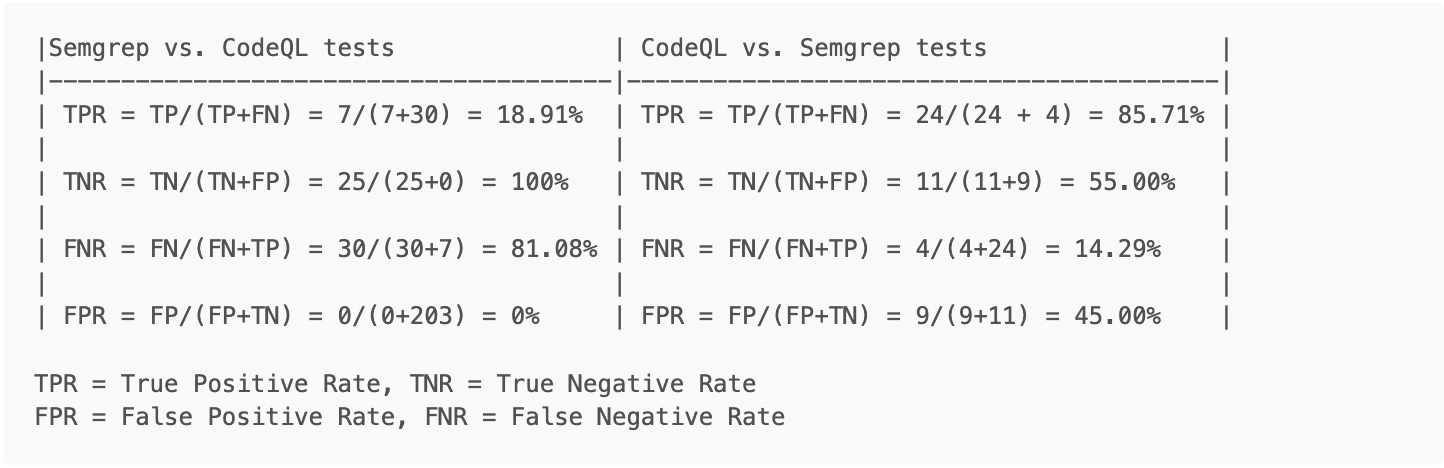
Notes:
Semgrep’s configuration was limited to only running rules classified as security-related and only against Golang files, for efficiency’s sake.
Semgrep successfully identified vulnerabilities associated with CWE-327, CWE-322 and CWE-319
Semgrep’s results only included two vulnerabilities which were the one intended to be found in the file (e.g., test for X find X). The remainder were HTTPs issues (CWE-319) related to servers configured for testing purposes in the CodeQL rules (e.g., test for X but find valid Y instead).
CodeQL rules for SQL injection did not perform well in this case (~20% detection), but did better in cross-site scripting and other tests. There were fewer overall rules available during testing, compared to Semgrep, and vulnerability classes like Server Side Template Injection (SSTI) were not checked for, due to the absence of rules.
Out of 14 files that CodeQL generated findings for, only 2 were analyzed without errors. 85% of files generated some errors during database creation.
False negative rates can increase dramatically if CodeQL fails to extract data from code. It is essential to make sure that there are not excessive extraction errors when creating a database or running any of the commands that implicitly run the extractors.
This section discusses the results of using the tools to examine an open source Golang project for one of our clients.
In these tests, due to the aforementioned lack of a priori knowledge of the code’s true security status, we are forced to assume that all files without true positives are free from vulnerabilities and are therefore considered TNs and likewise that there are no FNs. This underscores that testing against code that has already been organized for evaluation can be assumed as more accurate.
Running Semgrep with the “r2c-security-audit” configuration, resulted in 15 Golang findings, all of which were true positives. That said, the majority of the findings were related to the use of the unsafe library. Due to the nature of this issue, we opted to only count it as one finding per file, as to not further skew the results, by counting each usage within a file.
As shown in the table below, both tools performed very well! CodeQL detected significantly more findings, but it should be noted that they were largely the same couple of issues across numerous files. In other words, there were repeated code patterns in many cases, skewing the volume of findings.
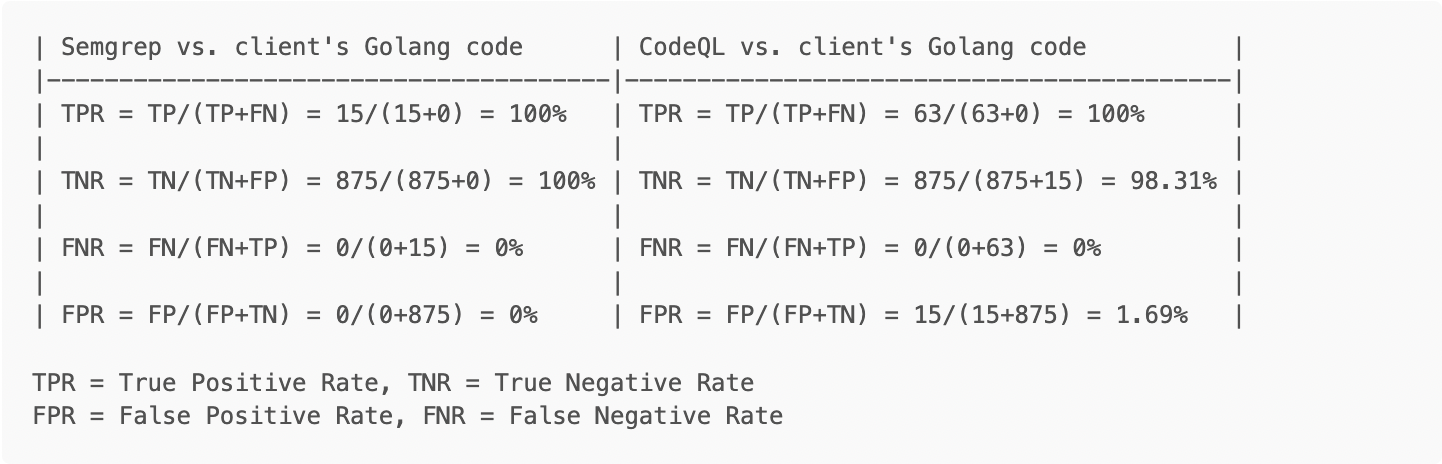
For the purposes of this exercise, TN = Total .go files - TP (890-15) = 875, since we are assuming all those files are free of vulnerabilities. For the Semgrep case, the value is irrelevant for the rate calculations, since no false positives were found.
Semgrep in --config auto mode resulted in thousands of findings when run against our client’s code, as opposed to tens of findings when limiting the scans to security-specific tests on Golang only. We cite this, to underscore that results will vary greatly depending on the code tested and rules applied. That reduction in scope resulted in no false positives during manually reviewed results.
For CodeQL, approximately 25% of the files were not scanned, due to issues with the tool
CodeQL encountered many errors during file compilation. 63 out of 74 Go files generated errors while being extracted to CodeQL’s database. This means that the analysis was performed on less data, and most files were only partially analyzed by CodeQL. This caused the CodeQL scan to result in significantly less findings than expected.
Obviously there could be some bias, but if you’d like another opinion, the creators of Semgrep have also provided a comparison with CodeQL on their website, particularly in this section : “How is Semgrep different from CodeQL?”.
Not surprisingly, in the end, we still feel Semgrep is a better tool for our use as a security consultancy boutique doing high-quality manual audits. This is because we don’t always have access to all the source code that we’d need to use CodeQL, the process of setting up scans is more laborious and time consuming in CodeQL. Additionally, we can manually vet findings ourselves - so a few extra findings isn’t a major issue for us and we can use it for free. If an organization’s use-case is more aligned with our client’s - being an organization that is willing to invest the time and effort, is particularly sensitive to false positives (e.g. running a scan during CI/CD) and doesn’t mind paying for the licensing, CodeQL might be a better choice for them.
When a Chrome user opens a site on the Internet that requests a permission, Chrome displays a large prompt in the top left corner. The prompt remains visible on the page until the user interacts with it, reloads the page, or navigates away. The permission prompt has Block and Allow buttons, and an option to close it. On top of this, Chrome 98 displays the full prompt only if the permission was triggered “through a user gesture when interacting with the site itself”. These precautionary measures are the only things preventing a malicious site from using APIs that could affect user privacy or security.

Since Chrome implements this pop-up box, how does Electron handle permissions? From Electron’s documentation:
“In Electron the permission API is based on Chromium and implements the same types of permissions. By default, Electron will automatically approve all permission requests unless the developer has manually configured a custom handler. While a solid default, security-conscious developers might want to assume the very opposite.”
This approval can lead to serious security and privacy consequences if the renderer process of the Electron application were to be compromised via unsafe navigation (e.g., open redirect, clicking links) or cross-site scripting. We decided to investigate how Electron implements various permission checks to compare Electron’s behavior to that of Chrome and determine how a compromised renderer process may be able to abuse web APIs.
The webcam, microphone, and screen recording functionalities present a serious risk to users when approval is granted by default. Without implementing a permission handler, an Electron app’s renderer process will have access to a user’s webcam and microphone. However, screen recording requires the Electron app to have configured a source via a desktopCapturer in the main process. This leaves little room for exploitability from the renderer process, unless the application already needs to record a user’s screen.
Electron groups these three into one permission, “media”. In Chrome, these permissions are separate. Electron’s lack of separation between these three is problematic because there may be cases where an application only requires the microphone, for example, but must also be granted access to record video. By default, the application would not have the capability to deny access to video without also denying access to audio. For those wondering, modern Electron apps seemingly handling microphone & video permissions separately, are only tracking and respecting the user choices in their UI. An attacker with a compromised renderer could still access any media.
It is also possible for media devices to be enumerated even when permission has not been granted. In Chrome however, an origin can only see devices that it has permission to use. The API navigator.mediaDevices.enumerateDevices() will return all of the user’s media devices, which can be used to fingerprint the user’s devices. For example, we can see a label of “Default - MacBook Pro Microphone (Built-in)”, despite having a deny-all permission handler.
")
To deny access to all media devices (but not prevent enumerating the devices), a permission handler must be implemented in the main process that rejects requests for the “media” permission.
The File System Access API normally allows access to read and write to local files. In Electron, reading files has been implemented but writing to files has not been implemented and permission to write to files is always denied. However, access to read files is always granted when a user selects a file or directory. In Chrome, when a user selects a file or directory, Chrome notifies you that you are granting access to a specific file or directory until all tabs of that site are closed. In addition, Chrome prevents access to directories or files that are deemed too sensitive to disclose to a site. These are both considerations mentioned in the API’s standard (discussed by the WICG).

For these three APIs, the renderer process is granted access by default. This means a compromised renderer process can read the clipboard, send desktop notifications, and detect when a user is idle.
Access to the user’s clipboard is extremely security-relevant because some users will copy passwords or other sensitive information to the clipboard. Normally, Chromium denies access to reading the clipboard unless it was triggered by a user’s action. However, we found that adding an event handler for the window’s load event would allow us to read the clipboard without user interaction.


To deny access to this API, deny access to the “clipboard-read” permission.
Sending desktop notifications is another security-relevant feature because desktop notifications can be used to increase the success rate of phishing or other social engineering attempts.

To deny access to this API, deny access to the “notifications” permission.
The Idle Detection API is much less security-relevant, but its abuse still represents a violation of user privacy.

To deny access to this API, deny access to the “idle-detection” permission.
For this API, the renderer process is granted access by default. Furthermore, the main process never receives a permission request. This means that a compromised renderer process can always read a user’s fonts. This behavior has significant privacy implications because the user’s local fonts can be used as a fingerprint for tracking purposes and they may even reveal that a user works for a specific company or organization. Yes, we do use custom fonts for our reports!

What can you do to reduce your Electron application’s risk? You can quickly assess if you are mitigating these issues and the effectiveness of your current mitigations using ElectroNG, the first SAST tool capable of rapid vulnerability detection and identifying missing hardening configurations. Among its many features, ElectroNG features a dedicated check designed to identify if your application is secure from permission-related abuses:

A secure application will usually deny all the permissions for dangerous web APIs by default. This can be achieved by adding a permission handler to a Session as follows:
ses.setPermissionRequestHandler((webContents, permission, callback) => {
return callback(false);
})
If your application needs to allow the renderer process permission to access some web APIs, you can add exceptions by modifying the permission handler. We recommend checking if the origin requesting permission matches an expected origin. It’s a good practice to also set the permission request handler to null first to force any permission to be requested again. Without this, revoked permissions might still be available if they’ve already been used successfully.
session.defaultSession.setPermissionRequestHandler(null);
As we discussed, these permissions present significant risk to users even in Electron applications setting the most restrictive webPreferences settings. Because of this, it’s important for security teams & developers to strictly manage the permissions that Electron will automatically approve unless the developer has manually configured a custom handler.
As promised in November 2021 at Hack In The Box #CyberWeek event in Abu Dhabi, we’re excited to announce that ElectroNG is now available for purchase at https://get-electrong.com/.

Our premium SAST tool for Electron applications is the result of many years of applied R&D! Doyensec has been the leader in Electron security since being the first security company to publish a comprehensive security overview of the Electron framework during BlackHat USA 2017. Since then, we have reported dozens of vulnerabilities in the framework itself and popular Electron-based applications.
We launched Electronegativity OSS at the beginning of 2019 as a set of scripts to aid the manual auditing of Electron apps. Since then, we’ve released numerous updates, educated developers on security best practices, and grown a strong community around Electron application security. Electronegativity is even mentioned in the official security documentation of the framework.
At the same time, Electron has established itself as the framework of choice for developing multi-OS desktop applications. It is now used by over a thousand public desktop applications and many more internal tools and custom utilities. Major tech companies are betting on this technology by devoting significant resources to it, and it is now evident that Electron is here to stay.
Considering the evolution of the framework and emerging threats, we had quickly realized that Electronegativity was in need of a significant refresh, in terms of detection and features, to be able to help modern companies in “building with security”.
At the end of 2020, we sat down to create a project roadmap and created a development team to work on what is now ElectroNG. In this blog post, we will highlight some of the major improvements over the OSS version. There is much more under the hood, and we will be covering more features in future posts and presentations.

If you’ve ever used Electronegativity, it would be obvious that ElectroNG is no longer a command-line tool. Instead, we’ve built a modern desktop app (using Electron!).
ElectroNG features a new decision mechanism to flag security issues based on improved HTML/JavaScript/Typescript parsing and new heuristics. After developing that, we improved all existing atomic and conditional checks to reduce the number of false positives and improve accuracy. There are now over 50 checks to detect misconfigurations and security vulnerabilities!
However, the most significant improvement revolves around the creation of Electron-dependent checks. ElectroNG will attempt to determine the specific version of the framework in use by the application and dynamically adjust the scan results based on that. Considering that Electron APIs and options change very frequently, this boosts the tool’s reliability in determining things that matter.
To provide a concrete example to the reader, let’s consider a lesser-known setting named affinity. Electron v2 introduced a new BrowserView/BrowserWindow webPreferences option for gathering several windows into a single process. When specified, web pages loaded by BrowserView/BrowserWindow instances with the same affinity will run in the same renderer process. While this setting was meant to improve performance, it leads to unexpected results across different Electron versions.
Let’s consider the following code snippet:
function createWindow () {
// Create the browser window.
firstWin = new BrowserWindow({
width: 800,
height: 600,
webPreferences: {
nodeIntegration: true,
affinity: "secPrefs"
}
})
secondWin = new BrowserWindow({
width: 800,
height: 600,
webPreferences: {
nodeIntegration: false,
affinity: "secPrefs"
}
})
firstWin.loadFile('index.html')
secondWin.loadFile('index.html')
Looking at the nodeIntegration setting defined by the two webPreferences definitions, one might expect the first BrowserWindow to have access to Node.js primitives while the second one to be isolated. This is not always the case and this inconsistency might leave an insecure BrowserWindow open to attackers.
The results across different Electron versions are surprising to say the least:

The affinity option has been fully deprecated in v14 as part of the Electron maintainers’ plan to more closely align with Chromium’s process model for security, performance, and maintainability. This example demonstrates two important things around renderers’ settings:
webPreferences are applicable and which aren’twebPreferences change based on the specific version of the frameworkElectroNG is available for online purchase at $688/year per user. Visit https://get-electrong.com/buy.html.
The license does not limit the number of projects, scans, or even installations as long as the software is installed on machines owned by a single individual person. If you’re a consultant, you can run ElectroNg for any number of applications, as long as you are running it and not your colleagues or clients. For bulk orders (over 50 licenses), contact us!
With the advent of ElectroNG, we have already received emails asking about the future of Electronegativity.
Electronegativity & ElectroNG will coexist. Doyensec will continue to support the OSS project as we have done for the past years. As usual, we look forward to external contributions in the form of pull requests, issues, and documentation.
ElectroNG’s development focus will be towards features that are important for the paid customers with the ultimate goal of providing an effective and easy-to-use security scanner for Electron apps. Having a team behind this new project will also bring innovation to Electronegativity since bug fixes and features that are applicable to the OSS version will be also ported.
As successfully done in the past by other projects, we hope that the coexistence of a free community and paid versions of the tool will give users the flexibility to pick whatever fits best. Whether you’re an individual developer, a small consulting boutique, or a big enterprise, we believe that Electronegativity & ElectroNG can help eradicate security vulnerabilities from your Electron-based applications.
Throughout the Summer of 2022, I worked as an intern for Doyensec. I’ll be describing my experience with Doyensec in this blog post so that other potential interns can decide if they would be interested in applying.
The recruitment process began with a non-technical call about the internship to make introductions and exchange more information. Once everyone agreed it was a fit, we scheduled a technical challenge where I was given two hours to provide my responses. I enjoyed the challenge and did not find it to be a waste of time. After the technical challenge, I had two technical interviews with different people (Tony and John). I thought these went really well for questions about web security, but I didn’t know the answers to some questions about other areas of application security I was less familiar with. Since Doyensec performs assessments of non-web applications as well (mobile, desktop, etc.), it made sense that they would ask some questions about non-web topics. After the final call, I was provided with an offer via email.
As an intern, my time was divided between working on an internal training presentation, conducting research, and performing security assessments. Creating the training presentation allowed me to learn more about a technical topic that will probably be useful for me in the future, whether at Doyensec or not. I used some of my research time to learn about the topic and make the presentation. My presentation was on the advanced features of Semgrep, the open-source static code analysis tool. Doyensec often has cross-training sessions where members of the team demonstrate new tools and techniques, or just the latest “Best Bug” they found on an engagement.
Conducting research was a good experience as an intern because it allowed me to learn more about the research topic, which in my case was Electron and its implementation of web API permissions. Don’t worry too much about not having a good research topic of your own already – there are plenty of things that have already been selected as options, and you can ask for help choosing a topic if you’re not sure what to research. My research topic was originally someone else’s idea.
My favorite part of the internship was helping with security assessments. I was able to work as a normal consultant with some extra guidance. I learned a lot about different web frameworks and programming languages. I was able to see what technologies real companies are using and review real source code. For example, before the internship, I had very limited experience with applications written in Go, but now I feel mostly comfortable testing Go web applications. I also learned more about mobile applications, which I had limited experience with. In addition to learning, I was able to provide actionable findings to businesses to help reduce their risk. I found vulnerabilities of all severities and wrote reports for these with recommended remediation steps.
When I was looking for an internship, I wanted to find a role that would let me learn a lot. Most of the other factors were low-priority for me because the role is temporary. If you really enjoy application security and want to learn more about it, this internship is a great way to do that. The people at Doyensec are very knowledgeable about a wide variety of application security topics, and are happy to share their knowledge with an intern.
Even though my priority was learning, it was also nice that the work is performed remotely and with flexible hours. I found that some days I preferred to stop work at around 2-3 PM and then continue in the night. I think these conditions are desirable to anyone, not just interns.
As for qualifications, Doyensec has stated that the ideal candidate:
My experience before the internship consisted mostly of bug bounty hunting and CTFs. There are not many other opportunities for college students with zero experience, so I had spent nearly two years bug hunting part-time before the internship. I also had the OSWE certification to demonstrate capability for source code review, but this is definitely not required (they’ll test you anyway!). Simply being an active participant in CTFs with a focus on web security and code review may be enough experience. You may also have some other way of learning about web security if you don’t usually participate in CTFs.
I enjoyed my internship at Doyensec. There was a good balance between learning and responsibility that has prepared me to work in an application security role at Doyensec or elsewhere.
If you’re interested in the role and think you’d make a good fit, apply via our careers page: https://www.careers-page.com/doyensec-llc. We’re now accepting candidates for the Fall Internship 2022.