ABOUT US
We are security engineers who break bits and tell stories.
Visit us
doyensec.com
Follow us
@doyensec
Engage us
info@doyensec.com
Blog Archive
© 2026 Doyensec LLC 
We are security engineers who break bits and tell stories.
Visit us
doyensec.com
Follow us
@doyensec
Engage us
info@doyensec.com
© 2026 Doyensec LLC
As more companies develop in-house services and tools to moderate access to production environments, the importance of understanding and testing these Zero Touch Production (ZTP) platforms grows 1 2. This blog post aims to provide an overview of ZTP tools and services, explore their security role in DevSecOps, and outline common pitfalls to watch out for when testing them.
“Every change in production must be either made by automation, prevalidated by software or made via audited break-glass mechanism.” – Seth Hettich, Former Production TL, Google
This terminology was popularized by Google’s DevOps teams and is the golden standard to this day. According to this picture, there are SREs, a selected group of engineers that can exclusively use their SSH production access to act when something breaks. But that access introduces reliability and security risks if they make a mistake or their accounts are compromised. To balance this risk, companies should automate the majority of the production operations while providing routes for manual changes when necessary. This is the basic reasoning behind what was introduced by the “Zero Touch Production” pattern.

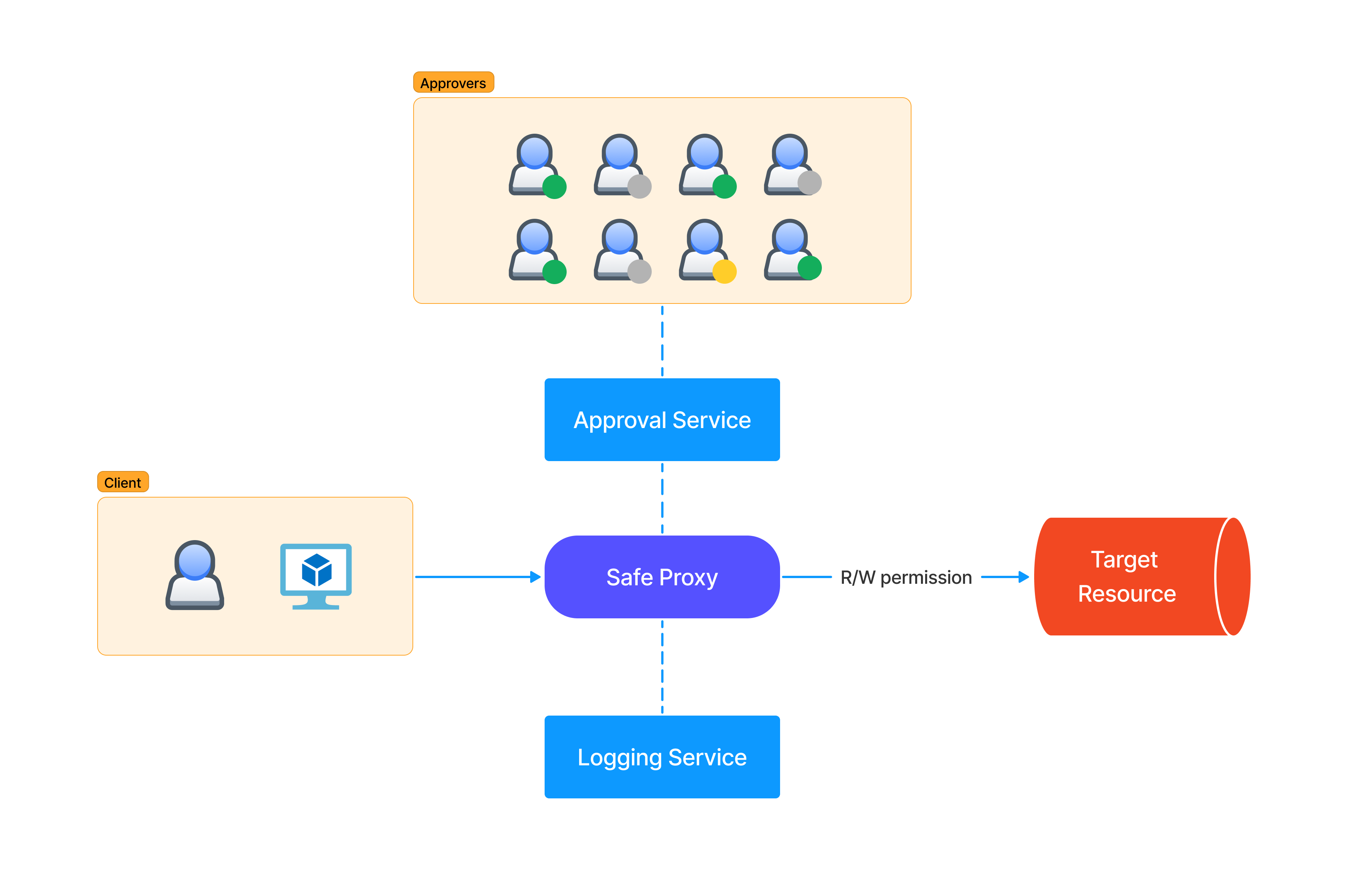
The “Safe Proxy” model refers to the tools that allow authorized persons to access or modify the state of physical servers, virtual machines, or particular applications. From the original definition:
At Google, we enforce this behavior by restricting the target system to accept only calls from the proxy through a configuration. This configuration specifies which application-layer remote procedure calls (RPCs) can be executed by which client roles through access control lists (ACLs). After checking the access permissions, the proxy sends the request to be executed via the RPC to the target systems. Typically, each target system has an application-layer program that receives the request and executes it directly on the system. The proxy logs all requests and commands issued by the systems it interacts with.
There are various outage scenarios prevented by ZTP (e.g., typos, cut/paste errors, wrong terminals, underestimating blast radius of impacted machines, etc.). On paper, it’s a great way to protect production from human errors affecting the availability, but it can also help to prevent some forms of malicious access. A typical scenario involves an SRE that is compromised or malicious and tries to do what an attacker would do with privileges. This could include bringing down or attacking other machines, compromising secrets, or scraping user data programmatically. This is why testing these services will become more and more important as the attackers will find them valuable and target them.
Many companies nowadays need these secure proxy tools to realize their vision, but they are all trying to reinvent the wheel in one way or another. This is because it’s an immature market and no off-the-shelf solutions exist. During the development, the security team is often included in the steering committee but may lack the domain-specific logic to build similar solutions. Another issue is that since usually the main driver is the DevOps team wanting operational safety, availability and integrity are prioritized at the expense of confidentiality. In reality, the ZTP framework development team should collaborate with SRE and security teams throughout the design and implementation phases, ensuring that security and reliability best practices are woven into the fabric of the framework and not just bolted on at the end.
Last but not least, these solutions are to this day suffering in their adoption rates and are subjected to lax intepretations (to a point where developers are the ones using these systems to access what they’re allowed to touch in production). These services are particularly juicy for both pentesters and attackers. It’s not an understatement to say that every actor compromising a box in a corporate environment should first look at these services to escalate their access.
We compiled some of the most common issues we’ve encountered while testing ZTP implementations below:
ZTP services often expose a web-based frontend for various purposes such as monitoring, proposing commands or jobs, and checking command output. These frontends are prime targets for classic web security vulnerabilities like Cross-Site Request Forgery (CSRF), Server-Side Request Forgery (SSRF), Insecure Direct Object References (IDORs), XML External Entity (XXE) attacks, and Cross-Origin Resource Sharing (CORS) misconfigurations. If the frontend is also used for command moderation, it presents an even more interesting attack surface.
Webhooks are widely used in ZTP platforms due to their interaction with team members and on-call engineers. These hooks are crucial for the command approval flow ceremony and for monitoring. Attackers may try to manipulate or suppress any Pagerduty, Slack, or Microsoft Teams bot/hook notifications. Issues to look for include content spoofing, webhook authentication weaknesses, and replay attacks.
Safety checks in ZTP platforms are usually evaluated centrally. A portion of the solution is often hosted independently for availability, to evaluate the rules set by the SRE team. It’s essential to assess the security of the core service, as exploiting or polluting its visibility can affect the entire infrastructure’s availability (what if the service is down? who can access this service?).
In an hypotetical sample attack scenario, if a rule is set to only allow reboots of a certain percentage of the fleet, can an attacker pollute the fleet status and make the hosts look alive? This can be achieved with ping reply spoofing or via MITM in the case of plain HTTP health endpoints. Under these premises, network communications must be Zero Trust too to defend against this.
The templates for the policy configuration managing the access control for services are usually provided to service owners. These can be a source of errors themselves. Users should be guided to make the right choices by providing templates or automatically generating settings that are secure by default. For a full list of the design strategies presented, see the “Building Secure and Reliable Systems” bible 3.
Inconsistent or excessive logging retention of command outputs can be hazardous. Attackers might abuse discrepancies in logging retention to access user data or secrets logged in a given command or its results.
Proper rate-limiting configuration is essential to ensure an attacker cannot change all production “at once” by themselves. The rate limiting configuration should be agreed upon with the team responsible for the mediated services.
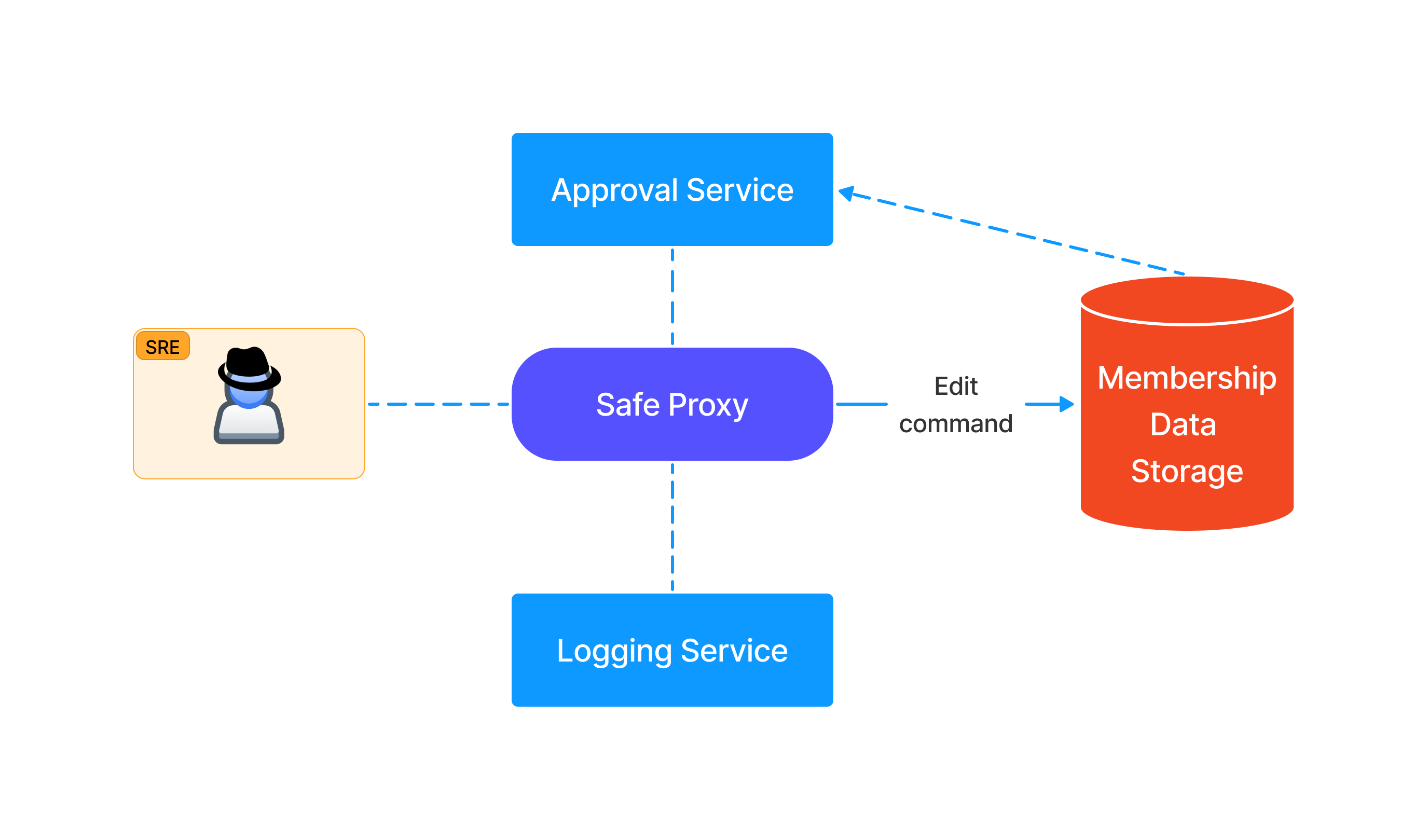
Another pitfall is found in what provides the ownership or permission logic for the services. If SREs can edit membership data via the same ZTP service or via other means, an attacker can do the same and bypass the solution entirely.
Strict allowlists of parameters and configurations should be defined for commands or jobs that can be run. Similar to “living off the land binaries” (lolbins), if arguments to these commands are not properly vetted, there’s an increased risk of abuse.
A reason for the pushed command must always be requested by the user (who, when, what, WHY). Ensuring traceability and scoping in the ZTP platform helps maintain a clear understanding of actions taken and their justifications.
The ZTP platform should have rules in place to detect not only if the user is authorized to access user data, but also which kind and at what scale. Lack of fine-grained authorization or scoping rules for querying user data increases the risk of abuse.
ZTP platforms usually have two types of proxy interfaces: Remote Procedure Call (RPC) and Command Line Interface (CLI). The RPC proxy is used to run CLI on behalf of the user/service in production in a controlled way. Since the implementation varies between the two interfaces, looking for discrepancies in the access requirements or logic is crucial.
The rule evaluation priority (Global over Service-specific) is another area of concern. In general, service rules should not be able to override global rules but only set stricter requirements.
If an allowlist is enforced, inspect how the command is parsed when an allowlist is created (abstract syntax tree (AST), regex, binary match, etc.).
All operations should be queued, and a global queue for the commands should be respected. There should be no chance of race conditions if two concurrent operations are issued.
In the ZTP pattern, a break-glass mechanism is always available for emergency response. Auditing this mode is essential. Entering it must be loud, justified, alert security, and be heavily logged. As an additional security measure, the breakglass mechanism for zero trust networking should be available only from specific locations. These locations are the organization’s panic rooms, specific locations with additional physical access controls to offset the increased trust placed in their connectivity.
As more companies develop and adopt Zero Touch Production platforms, it is crucial to understand and test these services for security vulnerabilities. With an increase in vendors and solutions for Zero Touch Production in the coming years, researching and staying informed about these platforms’ security issues is an excellent opportunity for security professionals.
Michał Czapiński and Rainer Wolafka from Google Switzerland, “Zero Touch Prod: Towards Safer and More Secure Production Environments”. USENIX (2019). Link / Talk ↩
Ward, Rory, and Betsy Beyer. “Beyondcorp: A new approach to enterprise security”, (2014). Link ↩
Adkins, Heather, et al. ““Building secure and reliable systems: best practices for designing, implementing, and maintaining systems”. O’Reilly Media, (2020). Link ↩