ABOUT US
We are security engineers who break bits and tell stories.
Visit us
doyensec.com
Follow us
@doyensec
Engage us
info@doyensec.com
Blog Archive
© 2025 Doyensec LLC 
There are many security solutions available today that rely on the Extended Berkeley Packet Filter (eBPF) features of the Linux kernel to monitor kernel functions. Such a paradigm shift in the latest monitoring technologies is being driven by a variety of reasons. Some of them are motivated by performance needs in an increasingly cloud-dominated world, among others. The Linux kernel always had kernel tracing capabilities such as kprobes (2.6.9), ftrace (2.6.27 and later), perf (2.6.31), or uprobes (3.5), but with BPF it’s finally possible to run kernel-level programs on events and consequently modify the state of the system, without needing to write a kernel module. This has dramatic implications for any attacker looking to compromise a system and go undetected, opening new areas of research and application. Nowadays, eBFP-based programs are used for DDoS mitigations, intrusion detection, container security, and general observability.
In 2021 Teleport introduced a new feature called Enhanced Session Recording to close some monitoring gaps in Teleport’s audit abilities. All issues reported have been promptly fixed, mitigated or documented as described in their public Q4 2021 report. Below you can see an illustration of how we managed to bypass eBPF-based controls, along with some ideas on how red teams or malicious actors could evade these new intrusion detection mechanisms. These techniques can be generally applied to other targets while attempting to bypass any security monitoring solution based on eBPF:
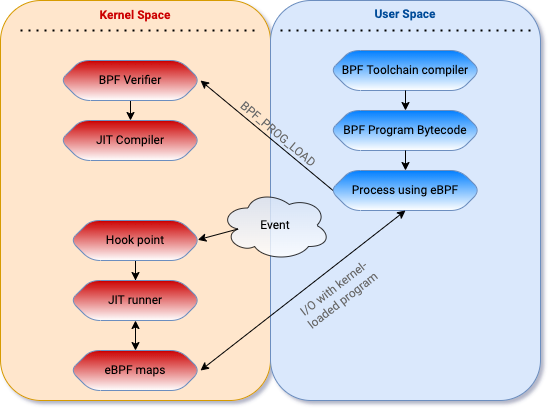
Extended BPF programs are written in a high-level language and compiled into eBPF bytecode using a toolchain. A user mode application loads the bytecode into the kernel using the bpf() syscall, where the eBPF verifier will perform a number of checks to ensure the program is “safe” to run in the kernel. This verification step is critical — eBPF exposes a path for unprivileged users to execute in ring 0. Since allowing unprivileged users to run code in the kernel is a ripe attack surface, several pieces of research in the past focused on local privilege exploitations (LPE), which we won’t cover in this blog post.
After the program is loaded, the user mode application attaches the program to a hook point that will trigger the execution when a certain hook point (event) is hit (occurs). The program can also be JIT compiled into native assembly instructions in some cases. User mode applications can interact with, and get data from, the eBPF program running in the kernel using eBPF maps and eBPF helper functions.
While eBPF is fast (much faster than auditd), there are plenty of interesting areas that can’t be reasonably instrumented with BPF due to performance reasons. Depending on what the security monitoring solution wants to protect the most (e.g., network communication vs executions vs filesystem operations), there could be areas where excessive probing could lead to a performance overhead pushing the development team to ignore them. This depends on how the endpoint agent is designed and implemented, so carefully auditing the code security of the eBPF program is paramount.
By way of example, a simple monitoring solution could decide to hook only the execve system call. Contrary to popular belief, multiple ELF-based Unix-like kernels don’t need a file on disk to load and run code, even if they usually require one. One way to achieve this is by using a technique called reflective loading. Reflective loading is an important post-exploitation technique usually used to avoid detection and execute more complex tools in locked-down environments. The man page for execve() states: “execve() executes the program pointed to by filename…”, and goes on to say that “the text, data, bss, and stack of the calling process are overwritten by that of the program loaded”. This overwriting doesn’t necessarily constitute something that the Linux kernel must have a monopoly over, unlike filesystem access, or any number of other things. Because of this, the execve() system call can be mimicked in userland with a minimal difficulty. Creating a new process image is therefore a simple matter of:
By following these six steps, a new process image can be created and run. Since this technique was initially reported in 2004, the process has nowadays been pioneered and streamlined by OTS post-exploitation tools. As anticipated, an eBPF program hooking execve would not be able to catch this, since this custom userland exec would effectively replace the existing process image within the current address space with a new one. In this, userland exec mimics the behavior of the system call execve(). However, because it operates in userland, the kernel process structures which describe the process image remain unchanged.
Other system calls may go unmonitored and decrease the detection capabilities of the monitoring solution. Some of these are clone, fork, vfork, creat, or execveat.
Another potential bypass may be present if the BPF program is naive and trusts the execve syscall argument referencing the complete path of the file that is being executed. An attacker could create symbolic links of Unix binaries in different locations and execute them - thus tampering with the logs.
Not hooking all the network-related syscalls can have its own set of problems. Some monitoring solutions may only want to hook the EGRESS traffic, while an attacker could still send data to a non-allowed host abusing other network-sensitive operations (see aa_ops at linux/security/apparmor/include/audit.h:78) related to INGRESS traffic:
OP_BIND, the bind() function shall assign a local socket address to a socket identified by descriptor socket that has no local socket address assigned.OP_LISTEN, the listen() function shall mark a connection-mode socket, specified by the socket argument, as accepting connections.OP_ACCEPT, the accept() function shall extract the first connection on the queue of pending connections, create a new socket with the same socket type protocol and address family as the specified socket, and allocate a new file descriptor for that socket.OP_RECVMSG, the recvmsg() function shall receive a message from a connection-mode or connectionless-mode socket.OP_SETSOCKOPT, the setsockopt() function shall set the option specified by the option_name argument, at the protocol level specified by the level argument, to the value pointed to by the option_value argument for the socket associated with the file descriptor specified by the socket argument. Interesting options for attackers are SO_BROADCAST, SO_REUSEADDR, SO_DONTROUTE.Generally, the network monitoring should look at all socket-based operations similarly to AppArmor.
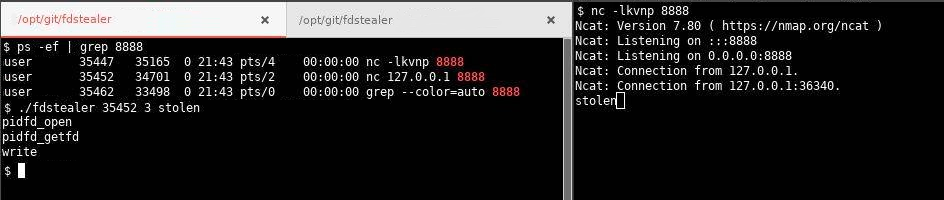
In case the same local user has mixed monitored and unmonitored console sessions, it could be possible for an attacker in a monitored session to leverage open file descriptors and sockets to send data to restricted hosts. In 2020 some versions of Linux kernels had introduced a new system call to achieve this called pidfd_getfd. A small number of operating systems (like Ubuntu) implement the Yama kernel module that limit file descriptor access to only child-parent processes. A PoC code for using this function is available on Github (TheZ3ro/fdstealer).
If only active console sessions are monitored, eBPF programs may only live for the time span of the session. By delaying the execution of a command (through sleep, timeout, sar, vmstat, inotifywait, at, cron …) and quitting the session, it could be possible to completely evade the solution.
cgroupA security monitoring solution may only be interested in auditing a specific user or cgroup (such in the context of a remote console session). Taking Teleport as an example, it achieves this by correlating every event to a session with control groups (cgroupv2 in particular). Control grouping is a Linux kernel feature to limit access to resources to a group of processes. It is used in many containerization technologies (behind the scenes Docker creates a set of namespaces and control groups for the container) and its peculiarity is that all child processes will keep the id of the parent process. When Teleport starts an SSH session, it first re-launches itself and places itself within a cgroup. This allows not only that process, but all future processes that Teleport launches, to be tracked with a unique ID. The BPF programs that Teleport runs have been updated to also emit the cgroup ID of the program executing them. The BPF script checks the value returned by bpf_get_current_cgroup_id() and only cares about the important session cgroup. The simplest evasion to this auditing strategy would be changing your cgroup ID, but an attacker needs to be root to achieve this. Meddling with the cgroupv2 pseudo file system or abusing PAM configuration are also potential opportunities to affect the cgroup/session correlation.
Another technique involves being reallocated by init. In the case of Teleport, when the bash process spawned by the session dies, its child processes become orphans and the Teleport process terminates its execution. When a child process becomes an orphan, it can be assigned to a different cgroup by the operating system under certain conditions (not having a tty, being a process group leader, joining a new process session). This allows an attacker to bypass the restrictions in place. The following PoC is an example of a bypass for this design:
tmux commandtmux by pressing CTRL+B and then Dtmux’s parenttmux process by executing tmux attach. The process tree will now look like this:
As another attack avenue, leveraging processes run by different local users/cgroupv2 on the machine (abusing other daemons, delegating systemd) can also help an attacker evade this. This aspect obviously depends on the system hosting the monitoring solution. Protecting against this is tricky, since even if PR_SET_CHILD_SUBREAPER is set to ensure that the descendants can’t re-parent themselves to init, if the ancestor reaper dies or is killed (DoS), then processes in that service can escape their cgroup “container”. Any compromise of this privileged service process (or malfeasance by it) allows it to kill its hierarchy manager process and escape all control.
BPF programs have a lot of constraints. Only 512 bytes of stack space are reserved for the eBPF program. Variables will get hoisted and instantiated at the start of execution, and if the script tries to dump syscall arguments or pt-regs, it will run out of stack space very quickly. If no workaround on the instruction limit is set, it could be possible to push the script into retrieving something too big to ever fit on the stack, losing visibility very soon when the execution gets complicated. But even when workarounds are used (e.g., when using multiple probes to trace the same events but capture different data, or split your code into multiple programs that call each other using a program map) there still may be a chance to abuse it. BPF programs are not meant to be run forever, but they have to stop at some point. By way of example, if a monitoring solution is running on CentOS 7 and trying to capture a process arguments and its environment variables, the emitted event could have too many argv and too many envp. Even in that case, you may miss some of them because the loop stops earlier. In these cases, the event data will be truncated. It’s important to note that these limitations are different based on the kernel where BPF is being run, and how the endpoint agent is written.
Another peculiarity of eBPFs is that they’ll drop events if they can not be consumed fast enough, instead of dragging down the performance of the entire system with it. An attacker could abuse this by generating a sufficient number of events to fill up the perf ringbuffer and overwrite data before the agent can read it.
The kernel-space understanding of a pid is not the same as the user-space understanding of a pid. If the eBPF script is trying to identify a file, the right way would be to get the inode number and device number, while a file descriptor won’t be as useful. Even in that case, probes could be subject to TOCTOU issues since they’ll be sending data to user mode that can easily change. If the script is instead tracing syscalls directly (using tracepoint or kprobe) it is probably stuck with file descriptors and it could be possible to obfuscate executions by playing around with the current working directory and file descriptors, (e.g., by combining fchdir, openat, and execveat).
seccomp-bpf & kernel discrepancieseBPF-based monitoring solutions should protect themselves by using seccomp-BPF to permanently drop the ability to make the bpf() syscall before spawning a console session. If not, an attacker will have the ability to make the bpf() syscall to unload the eBPF programs used to track execution. Seccomp-BPF uses BPF programs to filter arbitrary system calls and their arguments (constants only, no pointer dereference).
Another thing to keep in mind when working with kernels, is that interfaces aren’t guaranteed to be consistent and stable. An attacker may abuse eBPF programs if they are not run on verified kernel versions. Usually, conditional compilation for a different architecture is very convoluted for these programs and you may find that the variant for your specific kernel is not targeted correctly. One common pitfall of using seccomp-BPF is filtering on system call numbers without checking the seccomp_data->arch BPF program argument. This is because on any architecture that supports multiple system call invocation conventions, the system call numbers may vary based on the specific invocation. If the numbers in the different calling conventions overlap, then checks in the filters may be abused. It is therefore important to ensure that the differences in bpf() invocations for each newly supported architecture are taken into account by the seccomp-BPF filter rules.
Similarly to (6), it may be possible to interfere with the eBPF program loading in different ways, such as targeting the eBPF compiler libraries (BCC’s libbcc.so) or adapting other shared libraries preloading methods to tamper with the behavior of legit binaries of the solution, ultimately performing harmful actions. In case an attacker succeeds in altering the solution’s host environment, they can add in front of the LD_LIBRARY_PATH, a directory where they saved a malicious library having the same libbcc.so name and exporting all the symbols used (to avoid a runtime linkage error). When the solution starts, instead of the legit bcc library, it gets linked with the malicious library. Defenses against this may include using statically linked programs, linking the library with the full path, or running the program into a controlled environment.
Many thanks to the whole Teleport Security Team, @FridayOrtiz, @Th3Zer0, & @alessandrogario for the inspiration and feedback while writing this blog post.